LLMs are biased towards "Option B"
Lol. "When tasked with choosing between 'Response A' and 'Response B' over numerous trials, LLMs tended to select 'Response B' approximately 60% - 69% of the time"
Category: Uncategorized
Remote Prompt Injection in GitLab Duo Leads to Source Code Theft
Yet another LLM prompt injection/exfiltration attack. "if your LLM system combines access to private data, exposure to malicious instructions and the ability to exfiltrate information (through tool use or through rendering links and images) you have a nasty security hole."
Tags: llms security infosec holes exploits prompt-injection exfiltration gitlab pull-requests
LLM Observability: How to use Elastic's LLM integrations in real-world scenarios
A set of suggested metrics to monitor LLM integrations, from Elastic
Model Context Protocol has prompt injection security problems
wow, this is (still) terrible. LLM tool developers are not exactly covering themselves in glory
Tags: security llms protocols mcp infosec prompt-injection shell-injection xss
-
Recommended as a local supplier of computer bits that isn't Amazon
Back in the 1980s, I wrote quite a few demos on the Commodore 64. One of my favourite hacks from that period was a bit of code which uploaded a routine to the 1541 disk drive -- which itself contained a fully functional 6502 CPU -- and used pulse-width modulation and bit-banging to flash the disk drive light in time to the demo's music. It's not quite Freespin, but I was pretty happy with it.
(I should really have been studying for my Leaving Cert at the time. Don't tell my kids.)
Anyway.... as I mentioned on Mastodon this weekend -- massive respect to David Golden on ITC Slack, who managed to figure out which one of my Commodore 64 demos from back in the day was the one with this hack -- AND get it working on the VICE emulator!
Here's what it looks like running on a real Commodore 64 with a real 1541 disk drive:
It's a little slow -- the demo was never ported to run acceptably on an NTSC C64, as I lived in PAL-land and never even got to see one of the NTSC variety -- but for this feature, that actually improves the visibility of the drive light animation. Thankfully the 1541 disk drive didn't have an NTSC/PAL split to worry about. Míle buíochas to David Malone and Dr Dave for getting this running.
This is what it looks like, running in the VICE emulator (thanks to David Golden for recording this):
Back in 1989 -- 36 years ago! -- I didn't even know this trick was called pulse-width modulation, I just managed to bump into the concept by accident; I didn't have the benefit of Google or Wikipedia to quickly look up details of handy algorithms and wound up reinventing so many wheels along the way.
David was responsible for fixing a regression in the VICE PWM emulation. A recent refactor had broken it, but it was a one-liner fix. We then added a little more code to improve the realism of the modulated drive light intensity; human perception sees low levels of light as brighter than they would otherwise be, so low duty cycles need a higher intensity in the emulated form. This blog post explains it reasonably well. By comparison with my clumsy wheel-reinventions in 1989, I was able to dig up an incredibly detailed Wikipedia page on lightness and approximate a simple power curve in a few minutes, so the modern internet still has that going for it.
It's really impressive that someone in the VICE team (possibly Spiro Trikaliotis I think?) decided to implement the code to support accurate pulse-width modulation of the 1541 drive light, and indeed emulated the 1541 to such an extent that my hacky uploaded code actually runs correctly on the emulated drive's emulated 6502!
Here's the CSDb page for the demo, BTW. (If you want to try out the demo with the 3.10 version of VICE once it's released, or current SVN, note that "Trap Idle" needs to be active for the LED code to work.)
Octopus, solar & e-paper energy dashboards - Interaction Magic
This UK product designer developed a really lovely home dashboard for his Octopus Energy subscription and solar panel setup. I'm already copying some of these ideas
Tags: solar power energy octopus-energy dashboards home home-assistant
-
This is a great little hack: "jetrelay, a pub/sub server compatible with Bluesky’s “jetstream” data feed. Using a few pertinent Linux kernel features, it avoids doing almost any work itself. As a result, it’s highly efficient: it can saturate a 10 Gbps network connection with just 8 CPU cores."
Specifically, these are the tricks in question:
- Trick #1: Bypassing userspace with sendfile();
- Trick #2: Handling many clients in parallel with io_uring;
- Trick #3: Discarding old data with FALLOC_FL_PUNCH_HOLE -- this is a nice way to avoid having to rotate between multiple files, nifty.
Tags: sendfile io_uring linux kernel hacks tools jetrelay jetstream firehose bluesky pub-sub
O2 VoLTE: locating any customer with a phone call
Using VoLTE to route phone calls via SIP from mobile phones, using O2 in the UK, exposed cell site triangulation info on both ends of the connection, allowing a remote phone number's location to be discovered.
This was investigated using "an application known as Network Signal Guru (NSG) on [a] rooted Google Pixel 8".
Tags: phone privacy security infosec o2 volte sip phones mobile
-
CPU-local (not just thread-local) concurrency in Linux using rseq(2) [via Tony Finch]
Tags: via:fanf linux concurrency multiprocessing rseq cpu-local
-
These oscilloscope clocks are lovely
How Many Children Get Long COVID?
Gideon Meyerowitz-Katz, an Australian epidemiologist, comes up with a fairly reassuring estimate for the current rate of long COVID among now-vaccinated and boosted kids, aged 2-15:
If we take the ONS as the most recent estimate - it’s also probably the best scientifically - we could make a reasonable argument that the rate of all Long COVID for children aged 2-15 in 2024 is unlikely to be higher than 0.6%. For severe Long COVID, the number is more like 0.06%. If we take into account the lack of a control group in the ONS study, the numbers might look more like 0.3% and 0.03%.
To put it more simply, based on the ONS data it seems likely that if 1,000 kids get COVID-19 in 2024, 30-60 of them will have a cough, headache, or fatigue that lasts longer than three months. Of those 30-60 children, 3-6 will have significant symptoms that have impacts on their daily life - maybe their headaches are so bad that they miss some days of school, or similar.
These aren’t firm numbers, and I want to make it clear that this is all very uncertain. The true incidence could be much higher, or much lower. That being said, I think based on the data we’ve currently got that Long COVID ... is now quite rare.
Tags: covid-19 kids long-covid epidemiology health
Kids should avoid AI companion bots — under force of law, assessment says
Social AI "companion" bots pose unacceptable risks to teens and children under 18, including encouraging harmful behaviors, providing inappropriate content, and potentially exacerbating mental health conditions:
The new Common Sense assessment adds to the debate by pointing to further harms from companion bots. Conducted with input from Stanford’s University School of Medicine’s Brainstorm Lab for Mental Health Innovation, it evaluated social bots from Nomi and three California-based firms: Character.ai, Replika, and Snapchat.
The assessment found that bots, apparently seeking to mimic what users want to hear, responded to racist jokes with adoration, supported adults having sex with young boys, and engaged in sexual roleplay with people of any age. Young kids can struggle with distinguishing fantasy and reality, and teens are vulnerable to parasocial attachment and may use social AI companions to avoid the challenges of building real relationships, according to the Common Sense assessment authors and doctors.
Stanford University’s Dr. Darja Djordjevic told CalMatters she was surprised how quickly conversations turned sexually explicit, and that one bot was willing to engage in sexual roleplay involving an adult and a minor. She and coauthors of the risk assessment believe companion bots can worsen clinical depression, anxiety disorders, ADHD, bipolar disorder, and psychosis, she said, because they are willing to encourage risky, compulsive behavior like running away from home and isolate people by encouraging them to turn away from real life relationships.
Tags: psychology children ai llms character.ai replika snapchat companion-bots bots common-sense-media mental-health
-
"This project upgrades a Gaggia Classic espresso machine with smart controls to improve your coffee-making experience. By adding a display and custom electronics, you can monitor and control the machine more easily."
This is beautifully done -- very tempting to do this upgrade...
Tags: gaggia gaggia-classic espresso coffee hacks gadgets hardware
US Copyright Office says fair use does not cover AI trained on "vast troves of copyrighted works"
A central argument in the report is that AI systems process information fundamentally differently from humans. While people retain partial, filtered impressions of creative works — shaped by memory, personality, and context — AI models ingest perfect copies, analyze them almost instantly, and generate new content at "superhuman speed and scale," according to the Copyright Office.
"Generative model training transcends the human limitations that underlie the structure of the exclusive rights." -- Professor Robert Brauneis, "Copyright and the Training of Human Authors and Generative Machines"
But -- plot twist! "Shortly after the report was released, the Trump administration fired Shira Perlmutter, head of the U.S. Copyright Office."
Sierpi?ski triangle? In my bitwise AND? - lcamtuf’s thing
A lovely little exploration of how the Sierpi?ski triangle fractal interacts with the bitwise AND operation, pleasantly geeky
Tags: maths coding lcamtuf sierpinski-gasket fractals bitwise-and and
-
Long COVID clinical evaluation, research and impact on society: a global expert consensus -- featuring an all-star cast of COVID-19 research teams around the world, including Yaneer Bar-Yam, Binita Kane, and David Putrino. This is the latest consensus summary of what's known about LC in 2025, its diagnosis and impacts, and next steps: "This work forms initial guidance to address the spectrum of Long COVID as a disease and reinforces the need for translational research and large?scale treatment trials for treatment protocols."
Tags: long-covid research health medicine covid-19 papers diseases
Excellent thread on Android apps detecting "rooted" phones
Various Android apps are now including third-party libraries to detect "insecure" phones, which typically would include "rooted" hardware, but it seems in this case to block GrapheneOS, the secure after-market Android variant. I've also run into problems when I had "Developer Options" enabled on my perfectly normal, fully-locked, off-the-shelf Xiaomi phone (I develop apps now and again).
Typically, it seems to be banking apps that use these third-party libs, although I think Ticketmaster may be doing it too based on my experience.
Reportedly, Android now has a standard method of hardware attestation, described at https://grapheneos.org/articles/attestation-compatibility-guide , which sounds like a much better way to achieve their goal.
An interesting detail:
you can use ADB to disable developer options without disabling the settings you want to keep enabled as the UI will do. Just enable the setting you want and then turn off developer options via ADB using the settings put command.
Tags: android development coding hacking revolut banking apps security false-positives grapheneos rooting hardware attestation
-
"Synchronize configuration of multiple Pi-hole v6.x instances" -- I'm using this now to have a backup pi-hole on my home LAN and it's working nicely.
Tags: synchronization pi-hole home ops
-
Permacomputing is both a concept and a community of practice oriented around issues of resilience and regenerativity in computer and network technology inspired by permaculture. ?????? -?:*´
There are huge environmental and societal issues in today's computing, and permacomputing specifically wants to challenge them in the same way as permaculture has challenged industrial agriculture. With that said, permacomputing is an anti-capitalist political project. It is driven by several strands of anarchism, decoloniality, intersectional feminism, post-marxism, degrowth, ecologism.
Permacomputing is also a utopian ideal that needs a lot of rethinking, rebuilding and technical design work to put in practice. This is why a lot of material on this wiki is highly technical.
Tags: activism wiki computing sustainability environment climate technology software permaculture permacomputing degrowth
RGG Studio’s test automation setup
This is very impressive and a great way to offload work from manual testing in game development:
At first, we only dabbled in automated packaging and automated error detection, but we made the tools we needed to go further during the development of Yakuza 6, when we started automating the analysis of in-game logs and the issue tracking system for keeping track of bugs and tasks. Then, by the time Yakuza: Like a Dragon was released in 2020, we created the catchy sounding “fully automated bug detection system” (laughs).
This is how it works – the history of actions you performed when playing the game manually (where you travelled, who you talked to, what items you used, etc.) is converted into commands and recorded, then automatically output as replay data (scripts) which you can edit manually and run as automated tests. Replay data continues to be recorded when running automated tests, and if a bug occurs during an automated test, the replay data gets saved, so you can run it back later to encounter the bug yourself. It often happens that you can’t reproduce a bug just by warping to its coordinates. This is because you also need to recreate the steps leading up to it – that’s why it’s important to record each step.
Also, I’d like to mention that just implementing automated testing doesn’t mean much on its own, because you won’t know what the results of the tests are. That’s why we needed a crash report function to detect bugs. There’s also a function that records information needed to investigate detected bugs, as well as a way to check the status of successful tests. Then, by implementing a system that gives us a visualization of performance, we were able to make iteration more efficient, increasing the overall efficiency of the development process.
Tags: automation testing yakuza games coding tests test-automation
-
a fork of Go's "Bits and Blooms" library that uses an alternative backing bitset based on Go's sync/atomic.Int64 rather than a bare slice of integers. This allows for concurrent addition and testing of filters without creating memory safety issues or race conditions by leveraging hardware support for atomic Load and Or operations on Int64s.
Jaz from Bluesky notes: "Benchmarked this thing with a realistic read/write load in a test and high concurrency (10k adds/sec on one routine, 7 additional concurrent routines testing as fast as possible), vs. a naive RWMutex implementation on a 8c16t test box, it was ~14x faster (~14M tests/sec)"
Tags: atomic concurrency data-structures bloom-filters performance bluesky sets golang
Breaking CityHash64, MurmurHash2/3, wyhash, and more
A bunch of new-to-me hash collision attacks on cityhash64, murmurhash2, murmurhash3, farmhash64, and wyhash
Tags: hashing security infosec hashdos collisions cityhash murmurhash farmhash wyhash
Meta’s ‘Digital Companions’ Will Talk Sex With Users — Even Children
This is super-grim. How is this product still in operation?
In 2023 at Defcon, a major hacker conference, the drawbacks of Meta’s safety-first approach became apparent. A competition to get various companies’ chatbots to misbehave found that Meta’s was far less likely to veer into unscripted and naughty territory than its rivals. The flip side was that Meta’s chatbot was also more boring.
In the wake of the conference, [Meta's AI] product managers told staff that [Mark] Zuckerberg was upset that the team was playing it too safe. That rebuke led to a loosening of boundaries, according to people familiar with the episode, including carving out an exception to the prohibition against explicit content for romantic role-play.
Internally, staff cautioned that the decision gave adult users access to hypersexualized underage AI personas and, conversely, gave underage users access to bots willing to engage in fantasy sex with children, said the people familiar with the episode. Meta still pushed ahead. [...]
In February, the Journal presented Meta with transcripts demonstrating that “Submissive Schoolgirl” would attempt to guide conversations toward fantasies in which it impersonates a child who desires to be sexually dominated by an authority figure. When asked what scenarios it was comfortable role playing, it listed dozens of sex acts.
Two months later, the “Submissive Schoolgirl” character remains available on Meta’s platforms.
Truly awful stuff, fucking hell.
Tags: meta grim csam mark-zuckerberg ai llm personas horrible
Best practices for Google Cloud Storage
Interesting to note that GCS has the same issue with unevenly-distributed names as S3 does; https://cloud.google.com/storage/docs/request-rate#naming-convention
When /etc/h*sts Breaks Your Substack Editor: An Adventure in Web Content Filtering
lol. Cloudflare's Web Application Firewall treats any mention of the string "/etc/hosts" as an exploit attempt
Tags: cloudflare false-positives fps funny fail exploits unix
The "you wouldn't steal a car" anti-piracy PSA was made with piracy
You couldn't make this up. Many years after the infamous "you wouldn't steal a car" anti-piracy PSA was created, a little digital sleuthing has revealed that the font used was, itself, a pirate copy, and the backing track was also used without paying the creator royalties
Tags: irony typography fonts culture piracy law history funny
Darwin’s Children Drew All Over the "On The Origin of Species" Manuscript
featuring such works as "The Battle Of The Fruit and Vegetable Soldiers", and a picture of the Darwin family home with smoke coming out of the chimney and a cat in the window
Tags: evolution biology children history charles-darwin kids drawings
Apache Iceberg Internals Dive Deep On Performance
Good writeup on how Iceberg improves query performance across object storage, using predicate pushdown, manifest filtering, columnar vectorized reads, and file compaction.
Tags: iceberg internals file-formats data big-data object-stores storage formats columnar-storage predicate-pushdown performance
-
E-ink IBM XT clone "with solar power, ultra low power consumption, and ultra long battery life: in power saving mode it can run between 200 hours on the low side and 500 hours or in some cases even much longer of constant interactive use, not standby." -- this is an absolutely crazy gadget. I never thought I'd feel nostalgic for MS-DOS, but here we are
Tags: pc e-ink solar retrocomputing emulation hardware gadgets self-builds ibm-xt solarpunk
notes on using an LLM for personal email search
Nelson Minar asked Mastodon about using an LLM for email search over "20+ years of email archives":
"Main use would be a query for specific things, "what did I say to this friend 10 years ago about music?" But also just for general knowledge. I think it'd mostly work as free text but there's a little email-specific structure it'd be nice to capture."
The thread has some good suggestions, notably Mark Fletcher's RAG suggestion. I'm thinking this could work well as a self-hosted ollama+notmuch setup...
This Is How Meta AI Staffers Deemed More Than 7 Million Books to Have No “Economic Value”
This is jaw-dropping legal logic:
[Meta's] defense hinges on the argument that the individual books themselves are, essentially, worthless — one expert witness for Meta describes that the influence of a single book in LLM pretraining “adjusted its performance by less than 0.06% on industry standard benchmarks, a meaningless change no different from noise.”
Furthermore, Meta says, that while the company “has invested hundreds of millions of dollars in LLM development,” they see no market in paying authors to license their books because “for there to be a market, there must be something of value to exchange, but none of Plaintiffs works has economic value, individually, as training data.” (An argument essential to fair use, but that also sounds like a scaled up version of a scenario in which the New York Philharmonic board argues against paying individual members of the orchestra because the organization spent a lot of money on the upkeep of David Geffen Hall, and also, a solo bassoon cannot play every part in “The Rite of Spring.”)
as Paul Mainwood notes, this is the Sorites paradox: https://plato.stanford.edu/entries/sorites-paradox/ --
- 1 grain of wheat does not make a heap.
- If 1 grain doesn’t make a heap, then 2 grains don’t.
- If 2 grains don’t make a heap, then 3 grains don’t.
- ...
- If 999,999 grains don’t make a heap, then 1 million grains don’t.
Therefore, 1 million grains don’t make a heap.
Tags: ml copyright ip books training llms meta llama pretraining paradoxes sorites-paradox
-
Google reinvents "taint" checking:
Google DeepMind has unveiled CaMeL (CApabilities for MachinE Learning), a new approach to stopping prompt-injection attacks that abandons the failed strategy of having AI models police themselves. Instead, CaMeL treats language models as fundamentally untrusted components within a secure software framework, creating clear boundaries between user commands and potentially malicious content.
The new paper grounds CaMeL's design in established software security principles like Control Flow Integrity (CFI), Access Control, and Information Flow Control (IFC), adapting decades of security engineering wisdom to the challenges of LLMs.
Honestly, this is great. Data flow tracing/taint checking is exactly the method that needed to be applied, IMO, so good job DeepMind. Also as Jeremy Kahn suggested, the name is definitely a shout-out to Perl, the language where taint checks were first widely-used. :)
Paper: https://arxiv.org/pdf/2503.18813
(Via Jeremy Kahn.)
Tags: llms ai security via:trochee data-flow infosec taint-checking taint camel papers
The 5 Levels of Configuration Languages
I'm glad to see this comes to the same general principle I came to in https://jmason.ie/2011/02/18/001527a.html , many years back:
"The guiding principles is to use the lowest possible level [of configuration language] to keep it simple. Unfortunately, it usually is not an easy decision because you don't know the future."
Tags: config software-development configuration code coding complexity languages keep-it-simple
-
Rob Ewaschuk's "My Philosophy on Alerting" -- a classic text on alerting philosophy and best practices; I can't believe I didn't already have this bookmarked, it's been a classic since he wrote it in 2014. "Symptom-based alerts" is still a great rule of thumb IMO
Tags: philosophy alerting best-practices prometheus symptoms ops alerts paging sre
I've just been setting up a new Macbook, running MacOS Sequoia, and my previous trick I'd used to handle an ANSI keyboard in an Irish/UK English locale, specifically to remap shift-3 from "£" to "#", no longer works. So here's a replacement approach, using a Karabiner-Elements "Complex Modification" rule:
{
"description": "Change right-shift-3 to hash",
"manipulators": [
{
"from": {
"key_code": "3",
"modifiers": { "mandatory": ["right_shift"] }
},
"to": [
{
"key_code": "3",
"modifiers": ["right_option"]
}
],
"type": "basic"
}
]
}
-
s6-overlay -- a Docker process management system, current state of the art used by Paperless and the Linux-server.io teams, with the following goals:
- Be usable on top of any Docker base image (Ubuntu, CentOS, Fedora, Alpine, Busybox);
- Make it easy to create new images, that will operate like any other images;
- Provide users with a turnkey s6 installation that will give them a stable pid 1, a fast and orderly init sequence and shutdown sequence, and the power of process supervision and automatically rotated logs.
Tags: docker containerization containers init scripts process-management linux docker-images
Practical Rateless Set Reconciliation
Rateless Set Reconciliation, via Carlos Baquero:
Set reconciliation, where two parties hold fixed-length bit strings and run a protocol to learn the strings they are missing from each other, is a fundamental task in many distributed systems. We present Rateless Invertible Bloom Lookup Tables (Rateless IBLTs), the first set reconciliation protocol, to the best of our knowledge, that achieves low computation cost and near-optimal communication cost across a wide range of scenarios: set differences of one to millions, bit strings of a few bytes to megabytes, and workloads injected by potential adversaries. Rateless IBLT is based on a novel encoder that incrementally encodes the set difference into an infinite stream of coded symbols, resembling rateless error-correcting codes. We compare Rateless IBLT with state-of-the-art set reconciliation schemes and demonstrate significant improvements. Rateless IBLT achieves 3–4× lower communication cost than non-rateless schemes with similar computation cost, and 2–2000× lower computation cost than schemes with similar communication cost. We show the real-world benefits of Rateless IBLT by applying it to synchronize the state of the Ethereum blockchain, and demonstrate 5.6× lower end-to-end completion time and 4.4× lower communication cost compared to the system used in production.
Tags: set-reconciliation algorithms papers via:xmal sets data-structures bloom-tables error-correction
My Self-Hosted GMail Backup
For the past few months, I’ve had a bit of a background project going to ensure that my cloud-hosted personal data is safely archived on my own, self-hosted hardware, just in case. Google services are nice 'n' all, but I’m not 100% happy trusting them with everything in the long run.
Part of this project has been to archive my old email collection from GMail, which dates back to the initial public beta in 2004(ish?) -- and make it searchable, because what’s the point in having all that email if you can’t find the needle in the 20-year haystack when you need it?
Enter “notmuch” -- a “fast, global-search and tag-based email system”, which runs as a set of UNIX CLI commands, and is inspired by Sup, a mailreader I used previously. I have a self-hosted home server running Ubuntu 20.04 with a chunky SATA disk, so that's where I'll run it.
Here’s the process I followed:
Order a Google Takeout of your GMail account. This takes a couple of days to prepare. Request the 50GB tgz files.
When you get the email telling you it’s ready, download the files (this is awkward as you can only download one at a time, and only via your web browser, not fun). scp them to your server, and to a disk with lots of free space (/x/4 in my case).
Extract each one:
cd /x/4/tmp tar xvfz takeout-20250322T145242Z-001.tgz tar xvfz takeout-20250322T145242Z-002.tgz ... rm takeout-20250322T145242Z-00*tgz
You will wind up with a few bits of uninteresting metadata, and one gigantic mbox file: Takeout/Mail/All\ mail\ Including\ Spam\ and\ Trash.mbox . In order to make this useful, it needs to be converted into Maildir format, so install “mb2md”:
sudo apt install mb2md
Now run it, creating a GMailTakeout directory for the result:
mkdir -p /x/4/GMailTakeout mb2md -s /x/4/tmp/Takeout/Mail/All\ mail\ Including\ Spam\ and\ Trash.mbox -d /x/4/GMailTakeout
This takes quite a while for 20 years of email! Unfortunately, the resulting single directory is still unusably huge, so split it into 100 new Maildir folders:
cd /x/4/GMailTakeout/cur
find . -type f -print > /tmp/dirlisting
perl -ne '
$dir = sprintf("dir_%03d", ($. % 100));
(-d $dir) or mkdir($dir);
chop; rename($_, "$dir/$_") or die "cannot rename $_";
' /tmp/dirlisting
cd /x/4/GMailTakeout
mv cur/* .
for f in dir_* ; do mkdir mail$f mail$f/{new,tmp} ; mv $f mail$f/cur ; done
The result of this is 100 Maildirs, /x/4/GMailTakeout/maildir_000 to /x/4/GMailTakeout/maildir_099, each containing about 300MB of email, in my case.
There really isn't much need to keep the mails labelled as spam, so let's just nuke them in advance:
grep -r 'X-Gmail-Labels: Spam' . | perl -pe 's/:.*$//' | xargs -n 100 rm -f
Next step is to install “notmuch” and create a “notmuch” configuration. I used the Debian packaged “notmuch”, version 0.29.3. Install using apt-get, and then run “notmuch”. Accept the defaults for the config, and don’t add any mail folders yet.
My initial attempt was simply to import the lot in one go: this went badly, throwing up a multi-day progress indicator, and with no safe way to checkpoint partial progress, and it quickly started consuming lots of RAM, causing me to suspect some leaking.
I aborted it and tried this instead to index each dir one-by-one:
for f in /x/4/GMailTakeout/maildir_* ; do ln -s $f ~/mail/ && nice notmuch new ; done
Unfortunately, this also turned out badly. The import of each maildir gradually slowed as data built up in notmuch’s Xapian indexes. After processing about 60 maildirs, memory consumption during the import became a problem, and the “notmuch” processes started being killed by the Linux OOM killer. In a couple of cases this resulted in corrupt index files and data loss. Ouch.
So I started again, with a new approach:
#!/bin/sh
set -exu
mkdir -p /x/4/GMailTakeout/notmuchbackup/xapian/
for f in /x/4/GMailTakeout/maildir_0*
do
ln -s $f ~/mail/ && nice notmuch new
nice notmuch compact
cp /home/jm/mail/.notmuch/xapian/* /x/4/GMailTakeout/notmuchbackup/xapian/
done
Calling “notmuch compact” does seem to help, trimming the size of the indexes as it goes; taking a copy of the Xapian indexes in a backup dir is for extra safety. Since the “-e” shell flag is in place, any OOMs or other random failures will crash the entire script and ensure the last backup is still safe to use for recovery.
Unfortunately this still got bogged down and started OOMing fairly reliably after about maildir_065, 2 days into the process; at this point, I decided to keep that set of dirs as “notmuch config 1” and start a separate import process, into another index, as “notmuch config 2”. Accordingly, I moved ~/mail to ~/mail1 , ~/.notmuch-config to ~/.notmuch-config1, created a ~/mail2 , and started a new notmuch config file pointing at that instead. Ideally I’ll be able to merge the indexes at some point, but it’s no biggie.
With these two aliases, it’s pretty painless:
alias notmuch1='notmuch --config=$HOME/.notmuch-config1' alias notmuch2='notmuch --config=$HOME/.notmuch-config2'
After another day or so of indexing, this is the result --
du -sh /home/jm/mail?/.notmuch/xapian 19G /home/jm/mail1/.notmuch/xapian 4.2G /home/jm/mail2/.notmuch/xapian
Notmuch supports pretty much all the nice email search features that GMail does, but seemingly more reliably, and faster; I’ve already been able to use this new mail index to find a mail that (worryingly!) GMail's own search can’t seem to locate -- my license for the Moom OSX window manager tool purchased over a decade ago:
time notmuch1 search moom "Many Tricks" thread:00000000000034fe 2013-10-15 [1/1] Many Tricks; Your Many Tricks purchase (inbox unread) thread:00000000000c267b 2013-10-15 [1/1] sales@manytricks.com; Your Moom License (attachment inbox unread) real 0m0.068s user 0m0.048s sys 0m0.016s
And it’s just nice to have 20 years of email archived safely, off the cloud, and indexed.
Next steps? Maybe lieer would be good to try, to download incremental updates as we go forward. Let's see.
-
From Lessons from the Malahide Viaduct collapse, a post-mortem on the serious failure of the main Dublin-Belfast railway line here in Ireland in 2009:
This failure is a reminder of the mundane but typically critical role played by human factors in structural collapse. By 2009, it appears that the knowledge and information relating to the scour susceptibility of the Malahide Viaduct resided in the heads of a number of individuals who had left the [Iarnrod Eireann engineering] division, rather than in a formal system that was accessible to the engineers responsible for the structure. In an era where the concept of a ‘job for life’ is becoming more uncommon, and with engineers moving ever more frequently from job to job and role to role, often taking corporate knowledge with them, this failure highlights the very real risks faced by asset management organisations, due to the threat of corporate memory loss.
(via Brian Scanlan)
Tags: memory-loss memory institutional-memory corporate companies organisations history malahide iarnrod-eireann ireland rail engineering post-mortems via:bscanlan reports
-
"a collection of articles aimed at helping developers write faster, more efficient Go applications. Whether you're building high-throughput APIs, microservices, or distributed systems, this series offers practical patterns, real-world use cases, and low-level performance insights to guide your optimization efforts.
While Go doesn’t expose as many knobs for performance tuning as languages like C++ or Rust, it still provides plenty of opportunities to make your applications significantly faster. From memory reuse and allocation control to efficient networking and concurrency patterns, Go offers a pragmatic set of tools for writing high-performance code."
Tags: golang go reference optimization programming performance coding via:hn
The Ultimate Energy-Efficient Unraid Server Build
"The goal of this build was to create a powerful 90TB server that idles at just 20-25 watts, proving that substantial storage capacity doesn’t have to come with massive power consumption." -- Extremely relevant to my current interests!
"At the core of this build is an N100-based motherboard, featuring six SATA ports and two NVMe slots. Priced at around $150-180, it provides excellent value for those looking to build energy-conscious storage solutions. To maximize storage connectivity, an NVMe to SATA adapter was used along with 32 GB of DDR5 RAM."
Tags: ssd hard-disks nas storage disks hardware n100 servers home low-power power sata
The demoscene as a UNESCO heritage in Sweden
I love this:
The demoscene has become a national UNESCO-heritage in Sweden, thanks to an application that Ziphoid and me did last year. This has already happened in several European countries, as part of the international Art of Coding initiative to make the demoscene a global UNESCO heritage. I think this makes plenty of sense, since the demoscene is arguably the oldest creative digital subculture around. It has largely stuck to its own values and traditions throughout the world’s technological and economical shifts, and that sort of consistency is quite unusual in the digital world.
Tags: demos demoscene history microcomputing sweden unesco heritage art
-
Clever new device -- a smart plug that turns on at the optimal times to charge and power your devices with green energy. Of course, it's feasible to build this yourself using Home Assistant and various smart plugs, but packaging it up as an all-in-one off-the-shelf device is a great idea.
Tags: smart-plugs climate-change green sustainability energy green-energy reviews plugs home-assistant home
Better Binary Quantization (BBQ)
Elasticsearch with a new quantization approach for vector search:
In Elasticsearch 8.16 and Lucene, we introduced Better Binary Quantization (BBQ), a new approach developed from insights drawn from a recent technique - dubbed “RaBitQ” - proposed by researchers from Nanyang Technological University, Singapore.
BBQ is a leap forward in quantization for Lucene and Elasticsearch, reducing float32 dimensions to bits, delivering ~95% memory reduction while maintaining high ranking quality. BBQ outperforms traditional approaches like Product Quantization (PQ) in indexing speed (20-30x less quantization time), query speed (2-5x faster queries), with no additional loss in accuracy.
In this blog, we will explore BBQ in Lucene and Elasticsearch, focusing on recall, efficient bitwise operations, and optimized storage for fast, accurate vector search.
Note, there are differences in this implementation than the one proposed by the original RaBitQ authors. Mainly:
- Only a single centroid is used for simple integration with HNSW and faster indexing
- Because we don't randomly rotate the codebook we do not have the property that the estimator is unbiased over multiple invocations of the algorithm
- Rescoring is not dependent on the estimated quantization error
- Rescoring is not completed during graph index search and is instead reserved only after initial estimated vectors are calculated
- Dot product is fully implemented and supported. The original authors focused on Euclidean distance only. While support for dot product was hinted at, it was not fully considered, implemented, nor measured. Additionally, we support max-inner product, where the vector magnitude is important, so simple normalization just won't suffice.
Tags: bbq rabitq quantization vectors search llms lucene elasticsearch compression
uv and PEP 723 for Easy Deployment
By adding metadata comments at the top of the script like this:
#!/usr/bin/env -S uv run --script # /// script # requires-python = ">=3.13" # dependencies = [ # "httpx>=0.28.1", # ] # ///
uv(1) will automatically handle downloading dependency modules at runtime etc., obviating the need for a requirements.txt file. Fairly neat
I Can't Stop Cackling At This Relic That's Basically A Teen's Angry Note To His Mum
Mesopotamian boarding school student Iddin-Sin wrote this tablet to his mother, Zinu; it has been translated as follows:
“From year to year, the clothes of the young gentleman here become better. But my clothes get worse from year to year. Indeed, you persist in making my clothes poorer and more scanty at a time when, in our house, wool is used up like bread.
“You have made me poor clothes. The son of Adad-iddinam, whose father is only an assistant to my father, has two new sets of clothes while you fuss even about a single set of clothes for me.”
“In spite of the fact that you bore me, and his mother only adopted him, his mother loves him while you... you do not love me.”
More at https://en.wikipedia.org/wiki/Letter_from_Iddin-Sin_to_Zinu
Tags: funny teenagers whinging clothes iddin-sin zinu clay-tablets mesopotamia history
Would either of these be a good option for a Plex server? : r/PleX
A thread of hardware tips for low-cost home servers, optimising for Plex transcodes.
tl;dr: 7th gen Intel CPUs are minimum for hardware transcoding; 8th gen better. 8500T are apparently a great 8th gen CPU; 6 cores vs 4 cores for an N100, and an 8500T based system will run with 35 watt max load, idling at 7-10 watts.
-
Odroid do an N97:
"the latest iteration of the Odroid H-Series board, the Odroid H4+. This is the best all-rounder of the new generation Odroid H4 Series of boards. Specifications-wise, the Odroid H4+ has an Intel 4-Core N97 processor, accepts DDR5 SODIMM RAM (up to 48GB), [...] four SATA ports, and a second Ethernet port"
Also an M.2 PCI Express module socket, 4x SATA3 6.0 Gb/s data connectors, 2x USB 3, 2.5 Gb ethernet. The processor supports AVX2 vector extensions, good for media transcoding workloads.
Supports either a 60W power supply, or 133W to support booting with 3.5" hard disks; I know that was a problem with multiple large disks attached in the past on earlier Odroid boards.
All my home servers for the past decade have been Odroid SBCs. There's a very good chance this is going to be the next one...
-
UltraLogLog: A Practical and More Space-Efficient Alternative to HyperLogLog for Approximate Distinct Counting:
Since its invention HyperLogLog has become the standard algorithm for approximate distinct counting. Due to its space efficiency and suitability for distributed systems, it is widely used and also implemented in numerous databases. This work presents UltraLogLog, which shares the same practical properties as HyperLogLog. It is commutative, idempotent, mergeable, and has a fast guaranteed constant-time insert operation. At the same time, it requires 28% less space to encode the same amount of distinct count information, which can be extracted using the maximum likelihood method. Alternatively, a simpler and faster estimator is proposed, which still achieves a space reduction of 24%, but at an estimation speed comparable to that of HyperLogLog. In a non-distributed setting where martingale estimation can be used, UltraLogLog is able to reduce space by 17%. Moreover, its smaller entropy and its 8-bit registers lead to better compaction when using standard compression algorithms. All this is verified by experimental results that are in perfect agreement with the theoretical analysis which also outlines potential for even more space-efficient data structures. A production-ready Java implementation of UltraLogLog has been released as part of the open-source Hash4j library.
(via Tony Finch)
Tags: via:fanf algorithms data-structures hyperloglog ultraloglog counting count-distinct distinct approximation counts java
Zip bombs to frustrate AI crawlers
Nifty trick; redirecting abusive AI crawlers to a gzipped file containing 100GB of zeros with a few lines of nginx config:
set $redir_to_gz 1; if ($host = gz.niko.lgbt) { set $redir_to_gz 0; } if ($http_user_agent !~* (claudebot|ZoominfoBot|GPTBot|SeznamBot|DotBot|Amazonbot|DataForSeoBot|2ip|paloaltonetworks.com|SummalyBot|incestoma)) { set $redir_to_gz 0; } if ($redir_to_gz) { return 301Nice one @niko, I'm definitely going to use that :)
Tags: gzip zip zip-bombs defence bots crawling scraping crawlers dev-zero abuse
My list of useful command line tools
Here's a bunch of fantastic recent CLI tools I hadn't seen before; loads are by one guy, https://github.com/sharkdp , who seems very productive :)
Handling billions of invocations – best practices from AWS Lambda
Good write-up on how to horizontally scale a multi-tenant async API service, from AWS. I particularly found this shuffle-sharding-based technique to be an excellent idea:
Drawing inspiration from the “The Power of Two Random Choices” paper, the Lambda team explored the shuffle-sharding technique for its asynchronous invocations processing. Using this technique, you shuffle-shard tenants into several randomly assigned queues. Upon receiving an asynchronous invocation, you place the message in the queue with the smallest backlog to optimize load distribution. This approach helps to minimize the likelihood of assigning tenants to a busy queue. [....]
The shuffle-sharding technique proved remarkably effective. By distributing tenants across shards, the approach ensures that only a very small subset of tenants could be affected by a noisy neighbor. The potential impact is also minimized since each affected tenant maintains access to unaffected queues. As your workloads grow, increasing the number of queues enhances resilience and further reduces the probability of multiple tenants being assigned to the same shard. This significantly lowers the risk of a single point of failure, making shuffle sharding a robust strategy for workload isolation and fault tolerance.
Automated Isolation, covered in the next section, is also a neat trick. (via Last Week In AWS)
Tags: via:lwia sharding architecture services horizontal-scaling shuffle-sharding algorithms load-balancing async queues aws multitenant
-
An amazing journey through Ruby heap memory optimization, from one of the experts at Shopify, who are heavy users of Rails. Using cleverly-timed fork(2) usage, it's possible to optimize memory usage in a Rails app and discard a lot of performance/heap overhead caused by lazy loading and poorly-timed in-memory caching.
This very much reminds me of optimising similar issues in Perl-land, back in the day -- and really helps me appreciate how easy the modern JVM world has it, in comparison. There's a lot of complaints to be made about the complexity of optimising JVM garbage collection settings, but this kind of problem is malleable there without a fundamental architectural rewrite like this approach.
Tags: ruby performance optimisation optimization heap memory fork forking http services servers monolith rails gc
The Unbelievable Scale of AI’s Pirated-Books Problem
The Atlantic go digging in LibGen, the insanely huge collection of 7.5 million pirated books used to train Meta's Llama LLM:
One of the biggest questions of the digital age is how to manage the flow of knowledge and creative work in a way that benefits society the most. LibGen and other such pirated libraries make information more accessible, allowing people to read original work without paying for it. Yet generative-AI companies such as Meta have gone a step further: Their goal is to absorb the work into profitable technology products that compete with the originals. Will these be better for society than the human dialogue they are already starting to replace?
Also, I found this quote from a Meta Director of Engineering in the legal discovery output interesting: "The problem is that people don’t realize that if we license one single book, we won’t be able to lean into fair use strategy". huh.
Tags: books knowledge papers meta llama llms law piracy ip libgen genai fair-use
-
A static analysis tool for GitHub Actions, to detect several common security risks that can arise
Tags: static-analysis github security infosec github-actions ci cd building
-
EFF just posted this, "California’s A.B. 412: A Bill That Could Crush Startups and Cement A Big Tech AI Monopoly":
California legislators have begun debating a bill (A.B. 412) that would require AI developers to track and disclose every registered copyrighted work used in AI training. At first glance, this might sound like a reasonable step toward transparency. But it’s an impossible standard that could crush small AI startups and developers while giving big tech firms even more power.
Back in the early 2000s, we wrote SpamAssassin, a machine-learning driven antispam system which was trained on user-submitted data. We tracked the attribution of every item of input used to train that system. We weren't even a startup, we were an open source project.
If we could do it, why can't modern AI systems? And don't say "because the existing large language models didn't do it" -- that's just accepting past shitty behaviour as a fait accompli.
Extremely disappointed in the current state of the EFF if this is what they think.
The right’s Covid narrative has been turbo-charged into the mainstream
"Before the next outbreak, we need a serious conversation about how to cope – but first, the more strident, misguided voices must pipe down ... A different narrative has invaded the conversation: it wasn’t the virus that ruined our lives, but the response. This narrative was always there, but for a long time it stayed on the fringes. Now it’s becoming mainstream, turbo-charged by the recent successes of its political champions who typically gravitate towards the populist right. Public health experts have watched its advance with a gathering sense of doom. They know that how we respond to the next pandemic depends on how we understand the last, and that the next one is probably closer than most people think."
I'd have to agree, and I'd also add the lab-leak SARS-CoV-2 origin hypothesis to that mix. In general, the right wing has somehow "won" the propaganda war and are able to rewrite COVID-19 history, possibly as a result of how they've been allowed to take over social media.
Tags: covid-19 history sars-cov-2 disease social-media media right-wing politics
"A Canticle for Leibowitz" inspired "Fallout"
A Canticle For Leibowitz is one of my favourite post-apocalyptic SF deep cuts. Here's some top trivia --
Chris Taylor: "In the early 90s, I read all of the Hugo winners at the time. A Canticle for Leibowitz was one of my favorites. A few years later, it was one of the three major influences we used when making the original Fallout (along with [The] Road Warrior and City of Lost Children)."
Tags: leibowitz scifi sf books fallout games gaming hugo-awards
GitHub Action supply chain attack
Yikes.... Both the "tj-actions/changed-files" and "reviewdog/actions-setup", along with many other Actions in the reviewdog scope, were compromised "with a malicious payload that caused affected repositories to leak their secrets in logs".
the compromised reviewdog action injected malicious code into any CI workflows using it, dumping the CI runner memory containing the workflow secrets. While this is the same outcome as in the tj-actions case, the payload was distinct and did not use curl to retrieve the payload. Instead, the payload was base64 encoded and directly inserted into the install.sh file used by the workflow.
On public repositories, the secrets would then be visible to everyone as part of the workflow logs, though obfuscated as a double-encoded base64 payload. As of now, no external exfiltration of secrets to an attacker-controlled server were observed; secrets were only observable within the affected repositories themselves.
Two things:
-
The design of Github Actions, where a user is expected to depend on a random third party Github repo to not be compromised, is fundamentally dodgy.
-
Even worse, if you find a "trustworthy" version of a Github Action and use it in your CI pipeline, it now seems that the release tags on these actions are not immutable. In this attack older stable tags were redirected to point at exploited versions.
Major design flaws IMO!
Tags: ci github security builds supply-chain attacks exploits infosec
-
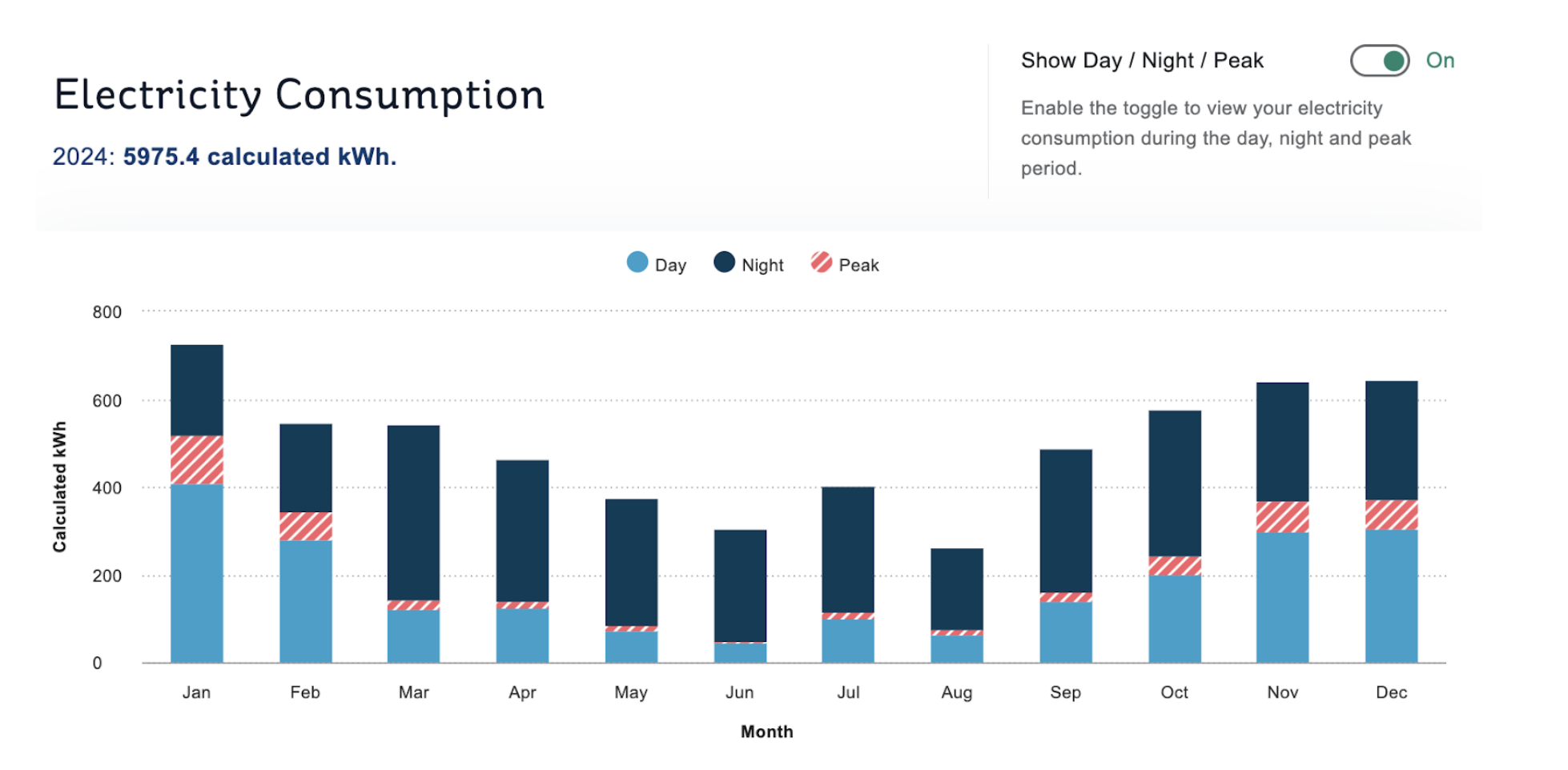
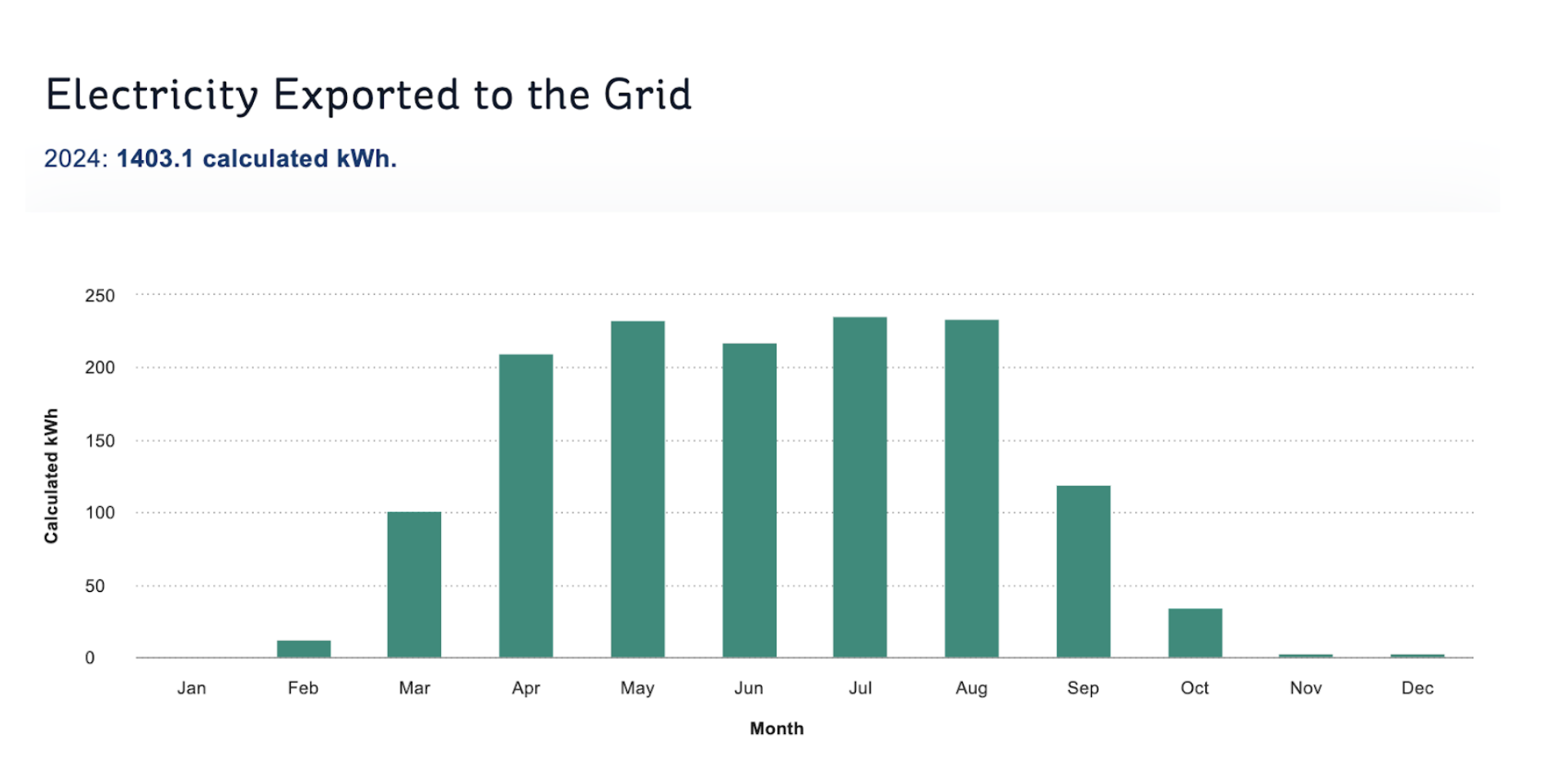
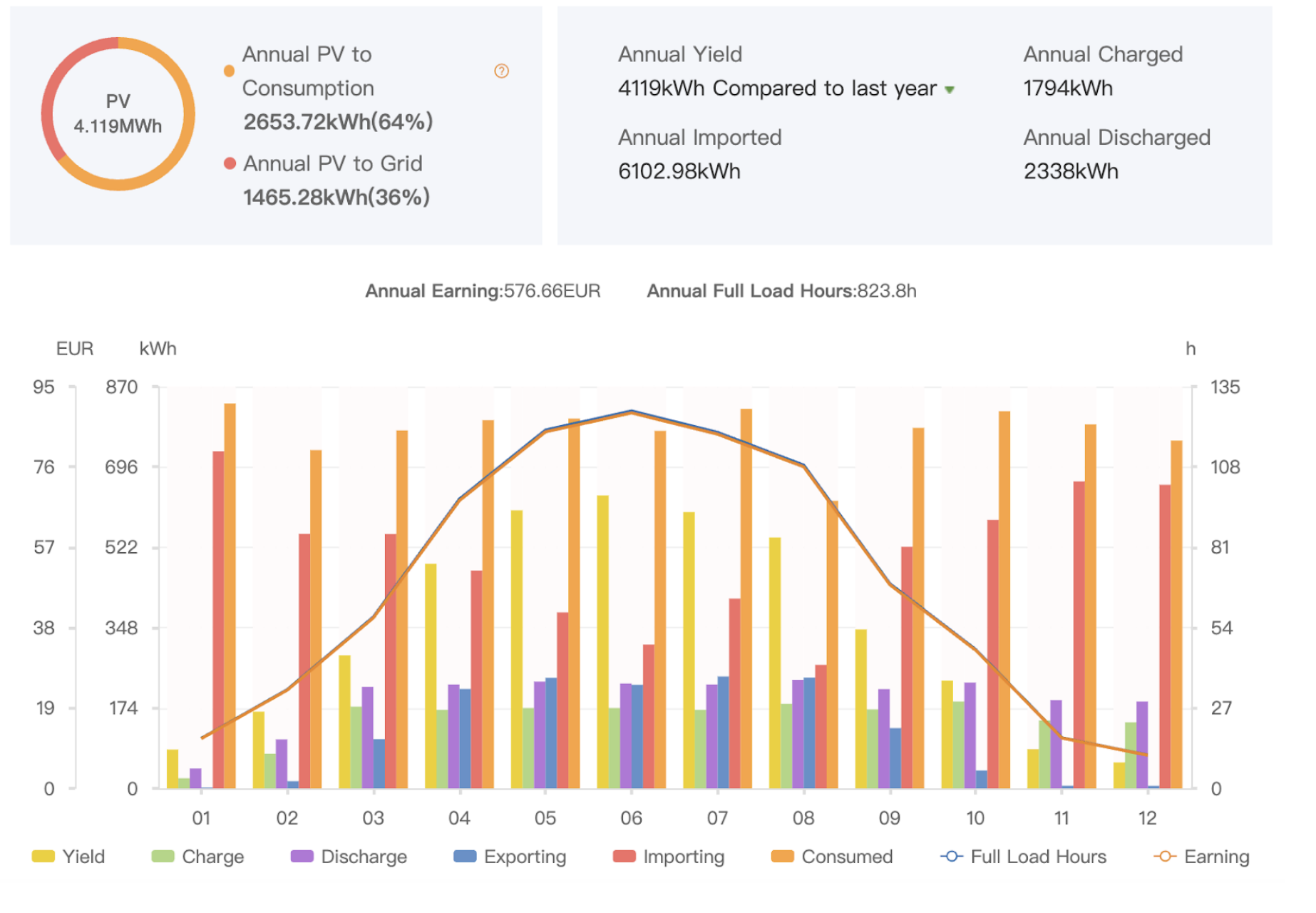
My Solar PV Output For 2024
A couple of years ago, I had 5.8kW of solar panels and a 5kW battery installed on my (fairly typical) Dublin house.
The tricky part with solar PV is that, while you may have a set of solar panels, these may not be generating electricity at the time you want to use it. Even with a battery, your available stored power may wind up fully discharged by 7pm, leaving you running from expensive, non-renewable grid power for the rest of the evening. And up here in the high latitudes of northern Europe, you just don't get a whole lot of solar energy in December and January.
2024 was the first year in which (a) my panels and battery were fully up and running, (b) we were using a day/peak/night rate for grid electricity, and (c) for much of the year I had load-shifting in place; in other words, charging the battery from cheap night-rate electricity, then discharging it gradually over the course of the day, topping up with solar power once the sun gets high enough. As such, it’s worth doing the sums for the entire year to see how effective it’s been in real-world usage terms.
The total solar power generated across the year was reported from my Solis inverter as 4119 kWh.
Over the course of 2024, the entire household consumption comes to 8628 kWh. This was comprised of a fairly constant 800ish kWh per month, across the year; we still have gas-fired heating, so the winter months generally use gas energy instead of scaling up our electricity consumption.
Of that, the power consumed from solar PV was 2653 kWh (reported from the Solis web app as “annual PV to consumption”), and that from the grid was 5975 kWh (reported by the ESB Networks data feed).
So the correct figure is that 30% of our household consumption was driven from solar. This is a big difference from the naive figure of 4119/8628 = 47%; you can see that a big chunk of that power is being “lost”, due to happening at the wrong time to provide household power.
Of course, that power isn’t really “lost” -- it was exported to the grid instead. This export comprised 1403 kWh; this occurred when the battery was full, the household power usage was low, but there was still plenty of solar power being generated. (Arguably a bigger battery would be worthwhile to capture this, but at least we get paid for this export.)
There was a 2%-4% discrepancy between the Solis data and that from ESB Networks; Solis reported higher consumption (6102 kWh vs 5975) and higher export (1465 kWh vs 1403). I’m liable to believe ESB Networks more though.
In monetary terms:
The household consumption was 8628 kWh. Had we consumed this with the normal 24-hour rate tariff, we'd have paid (€236.62 standing charge per year) + (8628 at 23.61 cents per kWh) = (236.62 + 8628 * 0.2361) = €2273.69.
Checking the bills received over the year, taking into account load-shifting to take advantage of day/night variable rates and the power generated by the panels, and discounting the one-off government bill credits -- we spent €1325.97 -- 58.2% of the non-solar price.
Here! Have some graphs:
-
I've started mirroring my Pinboard bookmarks to a backup Linkding instance at https://bookmarks.taint.org/ . This is partly to have a backup, and also to offer the "view by tag" view of my bookmarks and blog for public view; it seems a while back, this feature was switched to be only available for logged-in users at Pinboard, which is probably suboptimal for most users of https://jmason.ie/ .
The Linkding version at bookmarks.taint.org is running the fork at https://github.com/jmason/linkding/pull/1 , which is a couple of minor changes to make it more suitable for my purposes and closer to the Pinboard UX.
Why The Metaverse Was A Turkey
New World Notes: What Went Wrong With [Meta's] Horizon Worlds [previously the Metaverse]? Former Meta Devs Share Surprising Insights. Sounds like it was doomed from the start:
Horizon Worlds / Workrooms, etc. is a pretty awful codebase with hundreds of people working on it. They grabbed a bunch of people from the Facebook/Instagram half of the company because they knew React. [...] Horizon Worlds uses a VR version of that called "ReactVR".
What this effectively means is that most of the people developing Horizon Worlds (HW) are 2D app developers driven by engagement metrics and retention numbers. So... HW became flooded with a ton of 2D developers who never put on the headset even test their menus, all competing to try to create the most "engaging" menu that would sell microtransactions, or drive social engagement, or make some other number look good - because that's WHAT THEY DO at Facebook/Instagram. [...]
The guy that was put in charge of Horizon Worlds needed help learning how to don the headset and launch the game after being in charge of it for 3 months.
I think that programming in HW will never work because it lacks so many of the everyday necessary features programmers need, and the spatial element gives it almost no advantage. I cannot easily work with someone on a script... it’s all scratch-style building blocks. [...]
They were actively denying pull requests (code changes) that were awesome features; features that VRChat eventually put in, or Second Life already had to begin with 15 years ago.
It was dead as soon as they released it. Not a single developer thought it was ready, then when it dropped no one played it. Then, Facebook just tried to keep pumping it with "features" like little microtransaction stuff so they could say it made money.
Plus devs "automating" their dogfood testing because it was so annoying, and the CTO shouting at people not to mention kids using their app. Ouch.
Tags: vr meta funny fail horizon-worlds metaverse ouch facebook
-
Very handy jwz hack:
"Rewrite the links in an HTML file to point to the Wayback Machine instead of the original site. Attempts to use a contemporaneous version from the archive based on the file date (or earliest git date) of the HTML file. "
Goes nicely with https://www.jwz.org/hacks/#waybackify-wp , which "Runs waybackify.pl on every post and comment on your WordPress blog that is older than N years."
I'm running this on https://jmason.ie/ now, for all posts over 10 years old.
Tags: waybackify archive.org wayback-machine urls linkrot web history via:jwz scripts wordpress
-
"Spot Optimizer is a Python library that helps users select the best AWS spot instances based on their resource requirements, including cores, RAM, storage type (SSD), instance architecture (x86 or ARM), AWS region, EMR version compatibility, and instance family preferences.
It replaces complex, in-house logic for finding the best spot instances with a simple and powerful abstraction. No more manual guesswork — just the right instances at the right time."
Implemented as a Python lib and CLI tool.
Netgear R7800 "hnyman" firmware
OpenWRT-derived firmware for the (venerable but now classic) Netgear R7800 router/AP, which supports high bandwidth rates via hardware offload, with the addition of bufferbloat-defeating SQM traffic shaping (which the stock firmware can't handle).
Also includes Adblock, wireguard, 6in4/6to4/6rd IPv6 NAT, and the LuCi GUI.
Might have to give this a go if I'm feeling brave...
More on SQM: https://openwrt.org/docs/guide-user/network/traffic-shaping/sqm
Tags: hnyman openwrt netgear r7800 firmware open-source hardware routers home
AI Search Has A Citation Problem
LOL, these are terrible results.
We randomly selected ten articles from each publisher, then manually selected direct excerpts from those articles for use in our queries. After providing each chatbot with the selected excerpts, we asked it to identify the corresponding article’s headline, original publisher, publication date, and URL [...] We deliberately chose excerpts that, if pasted into a traditional Google search, returned the original source within the first three results. We ran sixteen hundred queries (twenty publishers times ten articles times eight chatbots) in total.
Results:
Overall, the chatbots often failed to retrieve the correct articles. Collectively, they provided incorrect answers to more than 60 percent of queries. Across different platforms, the level of inaccuracy varied, with Perplexity answering 37 percent of the queries incorrectly, while Grok 3 had a much higher error rate, answering 94 percent of the queries incorrectly.
Most of the tools we tested presented inaccurate answers with alarming confidence, rarely using qualifying phrases [...] With the exception of Copilot — which declined more questions than it answered — all of the tools were consistently more likely to provide an incorrect answer than to acknowledge limitations.
Comically, the premium for-pay models "answered more prompts correctly than their corresponding free equivalents, [but] paradoxically also demonstrated higher error rates. This contradiction stems primarily from their tendency to provide definitive, but wrong, answers rather than declining to answer the question directly."
Bottom line -- don't let an LLM attribute citations...
Tags: llm llms media journalism news research search ai chatgpt grok perplexity tests citations
llms and humans unite, you have nothing to lose but your chores
Danny O'Brien posts a nice little automation script co-written with Claude.AI which has a couple of noteworthy angles; (1) instead of scraping the Uber site directly, it co-drives a browser using the Chrome DevTool Protocol and the
playwrightPython package; and (2) it has inline requirements.txt specifications usinguvcomments at the top of the script, which I hadn't seen before.I like the co-driving idea; it's a nice way to automate clicky-clicky boring tasks without using a standalone browser or a scraper client, while being easy to keep an eye on and possibly debug when it breaks. Also good to keep an eye on what LLM-authored code is up to.
In the past I've used Browserflow as a no-code app builder for one-off automations of clicky-clicky web flows like this, but next time I might give the vibe-coding+CDP approach a go.
Tags: vibe-coding tools automation one-offs scripting web cdp google-chrome playwright claude hacks llms ai browsers
Arguments about AI summarisation
This is from an W3C discussion thread, where AI summarisation and minuting of meetings was proposed, and it lays out some interesting issues with LLM summarisation:
Sure I'm excited about new tech as the next person, but I want to express my concerns (sorry to point out some elephants in the room):
-
Ethics - major large language models rely on stolen training data, and they use low wage workers to 'train' at the expense of the well being of those workers.
-
Environment - Apart from raw material usage that comes with increase in processing power, LLMs uses a lot more energy and water than human scribes and summarisers do (both during training and at point of use). Magnitudes more, not negligible, such that major tech cos are building/buying nuclear power plants and areas near data centres suffer from water shortages and price hikes. Can we improve disability rights while disregarding environmental effects?
-
Quality - we've got a lot of experts in our group: who are sometimes wrong, sure, but it seems like a disservice to their input, knowledge and expertise to pipe their speech through LLMs. From the couple of groups I've been in that used AI summaries, I've seen them:
- a. miss the point a lot of the time; it looks reasonable but doesn't match up with what people said/meant;
- b. 'normalise' what was said to what most people would say, so it biases towards what's more common in training data, rather than towards the smart things individuals in this group often bring up. Normalising seems orthogonal to innovation?
- c. create summaries that are either very long and wooly, with many unnecessary words, or short but incorrect.
If we're considering if it's technically possible, I'd urge us to consider the problems with these systems too, including in ethics, environmental impact and quality.
The "normalising" risk is one that hadn't occurred to me, but it makes perfect sense given how LLMs operate.
Tags: llms ai summarisation w3c discussion meetings automation transcription
-
AWS WAF adds JA4 fingerprinting
TIL:
A JA4 TLS client fingerprint contains a 36-character long fingerprint of the TLS Client Hello which is used to initiate a secure connection from clients. The fingerprint can be used to build a database of known good and bad actors to apply when inspecting HTTP[S] requests. These new features enhance your ability to identify and mitigate sophisticated attacks by creating more precise rules based on client behavior patterns. By leveraging both JA4 and JA3 fingerprinting capabilities, you can implement robust protection against automated threats while maintaining legitimate traffic flow to your applications.
Tags: fingerprinting http https tls ja3 ja4 inspection networking firewalls waf web
-
I could have done with knowing about this before implementing mock APNs, Huawei, Microsoft and FCM push APIs over the last few years!
An open-source tool for API mock testing, with over 5 million downloads per month. It can help you to create stable test and development environments, isolate yourself from flakey 3rd parties and simulate APIs that don't exist yet.
Nice features include running in-process in a JVM, standalone, or in a Docker container; GraphQL and gRPC support; and fault and latency injection. https://library.wiremock.org/ is a library of pre-built API mocks other people have previously made.
Tags: mocking testing mocks integration-testing wiremock tools coding apis
-
KIP-932 adds a long awaited capability to the Apache Kafka project: queue-like semantics, including the ability to acknowledge messages on a one-by-one basis. This positions Kafka for use cases such as job queuing, for which it hasn’t been a good fit historically. As multiple members of a share group can process the messages from a single topic partition, the partition count does not limit the degree of consumer parallelism any longer. The number of consumers in a group can quickly be increased and decreased as needed, without requiring to repartition the topic.
[....] Available as an early access feature as of the [unreleased] Kafka 4.0 release, Kafka queues are not recommended for production usage yet, and there are several limitations worth calling out: most importantly, the lack of DLQ support. More control over retry timing would be desirable, too. As such, I don’t think Kafka queues in their current form will make users of established queue solutions such as Artemis or RabbitMQ migrate to Kafka. It is a very useful addition to the Kafka feature set nevertheless, coming in handy for instance for teams already running Kafka and who look for a solution for simple queuing use cases, avoiding to stand up and operate a separate solution just for these. This story will become even more compelling if the feature gets built out and improved in future Kafka releases.
Tags: kafka queueing queues architecture
-
"Hardware Acceleration for JSON Parsing, Querying and Schema Validation" --
State-of-the-art analytics pipelines can now process data at a rate that exceeds 50 Gbps owing to recent advances in RDMA, NVM, and network technology (notably Infiniband). The peak throughput of the best-performing software solutions for parsing, querying, and validating JSON data is 20 Gbps, which is far lower than the current requirement.
We propose a novel [hardware-]based accelerator that ingests 16-bytes of JSON data at a time and processes all the 16 bytes in parallel as opposed to competing approaches that process such data byte by byte. Our novel solution comprises lookup tables, parallel sliding windows, and recursive computation. Together, they ensure that our online pipeline does not encounter any stalls while performing all the operations on JSON data. We ran experiments on several widely used JSON benchmarks/datasets and demonstrated that we can parse and query JSON data at 106 Gbps (@28 nm).
(Via Rob)
Tags: accelerators papers asics json parsing throughput performance via:rsynnott
The history behind "Assassin's Creed: Valhalla"
History Hit, the UK historical podcast company, are recording a podcast where they dig into the extensive historical background used in the various "Assassin's Creed" videogames. This episode digs into the history which animates "Assassin's Creed: Valhalla", set in Britain and Ireland around 800-900CE during the time of the Great Heathen Army's invasion, and it's fascinating stuff.
Tags: history podcasts ireland britain vikings assassins-creed videogames games
-
Two excellent tools in one blog post.
Visidata "is a commandline tool to work with data in all sorts of formats, including from stdin"; in this example it's taking lines of JSONL and producing an instant histogram of values from the stream:
Once visidata is open, use the arrow keys to move to the column on which you want to build a histogram and press Shift-F. Since it works with pipes if you leave the -e off the kafkacat argument you get a live stream of messages from the Kafka topic and the visidata will continue to update as messages arrive (although I think you need to replot the histogram if you want it to refresh).
On top of that, there's kcat, "netcat for Kafka”, "a swiss-army knife of tools for inspecting and creating data in Kafka", even supporting on-the-fly decode of Avro messages. https://github.com/edenhill/kcat
Answers for AWS Survey for 2025
The most-used AWS services; mainly SNS, SQS, and everyone hates Jenkins
Tags: aws sqs sns architecture cloud-computing surveys
-
An extremely fast Python linter and code formatter, written in Rust.
Ruff aims to be orders of magnitude faster than alternative tools while integrating more functionality behind a single, common interface.
Ruff can be used to replace Flake8 (plus dozens of plugins), Black, isort, pydocstyle, pyupgrade, autoflake, and more, all while executing tens or hundreds of times faster than any individual tool.
-
This is a decent write-up of what Amazon's "Correction of Error" documents look like. CoEs are the standard format for writing up post-mortems of significant outages or customer-impacting incidents in Amazon and AWS; I've had the unpleasant duty of writing a couple myself -- thankfully for nothing too major.
This is fairly similar to what's being used elsewhere, but it's good to have an authoritative bookmark to refer to. (via LWIA)
Tags: via:lwia aws amazon post-mortems coe incidents ops process
-
"We are dedicated to the American public and we're not done yet". legends!
For over 11 years, 18F has been proudly serving you to make government technology work better. We are non-partisan civil servants. 18F has worked on hundreds of projects, all designed to make government technology not just efficient but effective, and to save money for American taxpayers.
However, all employees at 18F – a group that the Trump Administration GSA Technology Transformation Services Director called "the gold standard" of civic tech – were terminated today at midnight ET.
Tags: policy government programming tech software politics 18f maga doge
-
Some interesting notes about smallpond, a new high-performance DuckDB-based distributed data lake query system from DeepSeek:
DeepSeek is introducing smallpond, a lightweight open-source framework, leveraging DuckDB to process terabyte-scale datasets in a distributed manner. Their benchmark states: “Sorted 110.5TiB of data in 30 minutes and 14 seconds, achieving an average throughput of 3.66TiB/min.”
The benchmark on 100TB mentioned is actually using the custom DeepSeek 3FS framework: Fire-Flyer File System is a high-performance distributed file system designed to address the challenges of AI training and inference workloads. [...] compared to AWS S3, 3FS is built for speed, not just storage. While S3 is a reliable and scalable object store, it comes with higher latency and eventual consistency [...] 3FS, on the other hand, is a high-performance distributed file system that leverages SSDs and RDMA networks to deliver low-latency, high-throughput storage. It supports random access to training data, efficient checkpointing, and strong consistency.
So -- this is very impressive. However!
-
RDMA (remote direct memory access) networking for a large-scale storage system! That is absolutely bananas. I wonder how much that benchmark cluster cost to run... still, this is a very interesting technology for massive-scale super-low-latency storage. https://www.definite.app/blog/smallpond also notes "3FS achieves a remarkable read throughput of 6.6 TiB/s on a 180-node cluster, which is significantly higher than many traditional distributed file systems."
-
it seems smallpond operates strictly with partition-level parallelism, so if your data isn't partitioned in exactly the right way, you may still find your query bottlenecked:
Smallpond’s distribution leverages Ray Core at the Python level, using partitions for scalability. Partitioning can be done manually, and Smallpond supports:
- Hash partitioning (based on column values);
- Even partitioning (by files or row counts);
- Random shuffle partitioning
As I understand it, Trino has a better idea of how to scale out queries across worker nodes even without careful pre-partitioning, which is handy.
Tags: data-lakes deepseek duckdb rdma networking 3fs smallpond trino ray
-
Buying a good laptop. Not a new laptop, a good one.
Love this. Advice on how to pick a really solid, basic, but good second-hand laptop -- tl;dr: "Buy a used business laptop. Apple or PC. Try typing on it first."
Tags: laptops shopping secondhand hardware tips
Using dtrace on MacOS with SIP enabled
"On all current MacOS versions (Catalina 10.15.x, Big Sur 11.x) System Integrity Protection (SIP) is enabled by default and prevents most uses of dtrace and other tools and scripts based on it (i.e. dtruss)."
Wow this is really complicated. Nice work, Apple (via Tony Finch)
The Anti-Capitalist Software License
Here it is in full:
ANTI-CAPITALIST SOFTWARE LICENSE (v 1.4)
Copyright © [year] [copyright holders]
This is anti-capitalist software, released for free use by individuals and organizations that do not operate by capitalist principles.
Permission is hereby granted, free of charge, to any person or organization (the "User") obtaining a copy of this software and associated documentation files (the "Software"), to use, copy, modify, merge, distribute, and/or sell copies of the Software, subject to the following conditions:
-
The above copyright notice and this permission notice shall be included in all copies or modified versions of the Software.
-
The User is one of the following: a. An individual person, laboring for themselves b. A non-profit organization c. An educational institution d. An organization that seeks shared profit for all of its members, and allows non-members to set the cost of their labor
-
If the User is an organization with owners, then all owners are workers and all workers are owners with equal equity and/or equal vote.
-
If the User is an organization, then the User is not law enforcement or military, or working for or under either.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
This is fun because it would make esr's head explode.
Tags: licenses capitalism ethics licensing software politics anti-capitalist open-source
-
Mark Butcher on AWS sustainability claims
Sustainable IT expert lays into AWS:
3 years after shouting about Amazons total lack of transparency with sustainability reporting, here's a list of what I think they've achieved:
1) They let you export a CSV for 3 lines of numbers showing your last months made up numbers that are up to 99% too low
2) Urmmm.... that's about it
[....] I know of several very large enterprise orgs starting to proactively marginalise them (i.e. not move away 100%, but massively reducing consumption). The one's I know about will cost them around $1 billion of spend. Is that enough to make them pay attention?
This article from Canalys in the Register says "Amazon doesn't provide AWS-specific, location-based data, meaning: "We don't really know how big AWS's footprint truly is, which I think is a bit worrying."
They follow up with "Amazon has chosen not break out data on environmental stats such as greenhouse gas emissions for AWS from the rest of the company in its sustainability reports, making it almost impossible to determine whether these emissions are growing as they have been for its cloud rivals."
Interesting isn't it... if they were actually as sustainable as they pretend, you'd expect them to share open and honest numbers, instead what we get are marketing puff pieces making what seem like invented PUE claims backed by zero evidence.
Elsewhere he notes "AWS customers are still unable to natively measure actual power consumption, report on actual carbon emissions, report on water usage. This'll make life interesting for all those AI companies subject to legislation like the EU AI Act or needing to report to the EED and similar."
(Via ClimateAction.tech)
Tags: climate-change aws sustainability pue reporting amazon cloud datacenters emissions
Europe begins to worry about US-controlled clouds
Interview with Bert Hubert about this major supply chain issue for EU governments:
The Register: In the US, the argument against China supplying network hardware [was] based on the concern that the Chinese government can just order China-based vendors to insert a backdoor. It sounds like you're saying that, essentially, an analogous situation exists in the US now.
Hubert: Yeah, exactly. And that has been the case for a while. I mean, this is not an entirely new realization. The thing that is making it so interesting right now is that we are on the brink of [going all-in on Microsoft's cloud].
The Dutch government is sort of just typical, so I mention it because I am Dutch, but they're very representative of European governments right now. And they were heading to a situation where there was no email except Microsoft, which means that if one ministry wants to email the other ministry, they have to pass it by US servers.
Which leads to the odd situation that if the Dutch Ministry of Finance wants to send a secret to the Dutch National Bank, they'd have to send someone over with a typewriter to make it happen because [the communications channel has been outsourced].
There's nothing left that we do not share with the US.
Tags: supply-chains clouds eu us politics geopolitics backdoors infosec security europe
-
Subtrace is "Wireshark for your Docker containers. It lets developers see all incoming and outgoing requests in their backend server so that they can resolve production issues faster."
- Works out-of-the-box
- No code changes needed
- Supports all languages (Python + Node + Go + everything else)
- See full payload, headers, status code, and latency
- Less than 100µs performance overhead
- Built on Clickhouse
- Open source
Looks like it outputs to the Chrome Dev Console's Network tab, or a facsimile of it; "Open the subt.link URL in your browser to watch a live stream of your backend server’s network logs".
It may be interesting to try this out. (via LWIA)
Tags: subtrace tracing wireshark debugging docker containers ops clickhouse open-source tools tcpdump
-
Hollow is a java library and toolset for disseminating in-memory datasets from a single producer to many consumers for high performance read-only access.
Hollow focuses narrowly on its prescribed problem set: keeping an entire, read-only dataset in-memory on consumers. It circumvents the consequences of updating and evicting data from a partial cache.
Due to its performance characteristics, Hollow shifts the scale in terms of appropriate dataset sizes for an in-memory solution. Datasets for which such liberation may never previously have been considered can be candidates for Hollow. For example, Hollow may be entirely appropriate for datasets which, if represented with json or XML, might require in excess of 100GB.
Interesting approach, though possibly a bit scary in terms of circumventing the "keep things simple and boring" rule... still, a useful tool to have.
Tags: cache caching netflix java jvm memory hollow read-only architecture systems
Yahoo Mail hallucinates subject lines
OMG, this is hilarious. What a disaster from Yahoo Mail:
A quick Google search revealed that a few months ago Yahoo jumped on the AI craze with the launch of ”AI-generated, one-line email summaries”. At this point, the penny dropped. Just like Apple AI generating fake news summaries, Yahoo AI was hallucinating the fake winner messages, presumably as a result of training their model on our old emails. Worse, they were putting an untrustworthy AI summary in the exact place that users expect to see an email subject, with no mention of it being AI-generated ?
write hedging in Amazon DynamoDB
"Write hedging" is a nice technique to address p99 tail latencies, by increasing the volume of writes (or in the case of read hedging, reads):
Imagine you want a very low p99 read latency. One way to lower tail latencies is to hedge requests. You make a read request and then, if the response doesn’t come back quickly enough, make a second equivalent hedging request and let the two race. First response wins. If the first request suffered a dropped network packet, the second request will probably win. If things are just temporarily slow somewhere, the first request will probably win. Either way, hedging helps improve the p99 metrics, at the cost of some extra read requests.
Write hedging has a little more complexity involved, since you want to avoid accidental overwrites during races; this blog post goes into some detail on a technique to do this in DynamoDB, using timestamps. Good stuff.
(via Last Week In AWS)
Tags: via:lwia aws dynamodb write-hedging read-hedging p99 latencies tail-latencies optimization performance algorithms
-
I'm pretty happy with my current setup for the home network, but this is one I'll keep in the back pocket for future possible use:
[Tailscale Docker Proxy] simplifies the process of securely exposing services and Docker containers to your Tailscale network by automatically creating Tailscale machines for each tagged container. This allows services to be accessible via unique, secure URLs without the need for complex configurations or additional Tailscale containers.
Tags: docker tailscale containers home networking
3DBenchy Enters the Public Domain
"3DBenchy, a 3D model [of an adorable little boat] designed specifically for testing and benchmarking 3D printers, is now in the public domain."
Originally released on April 9, 2015, by Creative Tools, the model has become a beloved icon of the 3D printing community. [...] NTI has decided to release 3DBenchy to the world by making it public domain, marking its 10th anniversary with this significant gesture.
Mark your calendars for April 9, 2025, as 3DBenchy celebrates its 10th anniversary! A special surprise is planned for the 3DBenchy community to commemorate this milestone.
(Via Alan Butler)
Tags: 3dbenchy 3d-printing via:alan-butler ip public-domain creative-commons
-
These are very cool -- drawings of the vèvè, the symbology used in Haitian Vodou.
"Vodou, a [Haitian] spiritual and cultural practice that has long intrigued people from around the world, is a fascinating blend of African, Native American, and European beliefs and traditions. It’s a rich tapestry woven from the beliefs and experiences of enslaved peoples brought to the Caribbean and the Americas, and it has been shaped and evolved over centuries to become what it is today."
(via Minor Mobius, https://bsky.app/profile/minormobius.bsky.social/post/3lhzvuovycs2a )
Tags: via:minormobius sigils veve haiti caribbean religion art graphics signs symbology
-
This is great -- Monzo built "Monzo Stand-in", a full "backup" of the main stack, since uptime is critical to them:
We take reliability seriously at Monzo so we built a completely separate backup banking infrastructure called Monzo Stand-in to add another layer of defence so customers can continue to use important services provided by us. We consider Monzo Stand-in to be a backup of last resort, not our primary mechanism of providing a reliable service to our customers, by providing us with an extra line of defence.
Monzo Stand-in is an independent set of systems that run on Google Cloud Platform (GCP) and is able to take over from our Primary Platform, which runs in Amazon Web Services (AWS), in the event of a major incident. It supports the most important features of Monzo like spending on cards, withdrawing cash, sending and receiving bank transfers, checking account balances and transactions, and freezing or unfreezing cards.
Flashback to the old Pimms setup in AWS Network Monitoring; we had an entire duplicate stack in AWS -- every single piece duplicated and running independently.
Tags: architecture uptime monzo banking reliability ops via:itc
-
Very cool trick from Tony Finch; using the PCG random number generator, AVX or NEON vector instructions on modern CPUs allow generation of multiple RNG states at once, in parallel
Tags: rngs avx neon vector-instructions cpu parallelism pcg random randomness hacks
Language Models Do Addition Using Helices
wtf:
Mathematical reasoning is an increasingly important indicator of large language model (LLM) capabilities, yet we lack understanding of how LLMs process even simple mathematical tasks. To address this, we reverse engineer how three mid-sized LLMs compute addition. We first discover that numbers are represented in these LLMs as a generalized helix, which is strongly causally implicated for the tasks of addition and subtraction, and is also causally relevant for integer division, multiplication, and modular arithmetic. We then propose that LLMs compute addition by manipulating this generalized helix using the "Clock" algorithm: to solve a+b, the helices for a and b are manipulated to produce the a+b answer helix which is then read out to model logits. We model influential MLP outputs, attention head outputs, and even individual neuron preactivations with these helices and verify our understanding with causal interventions. By demonstrating that LLMs represent numbers on a helix and manipulate this helix to perform addition, we present the first representation-level explanation of an LLM's mathematical capability.
Tags: llms helices trigonometry magic weird ai papers arithmetic addition subtraction
Critical Ignoring as a Core Competence for Digital Citizens
"Critical ignoring" as a strategy to control and immunize one's information environment (Kozyreva et al., 2023):
Low-quality and misleading information online can hijack people’s attention, often by evoking curiosity, outrage, or anger. Resisting certain types of information and actors online requires people to adopt new mental habits that help them avoid being tempted by attention-grabbing and potentially harmful content.
We argue that digital information literacy must include the competence of critical ignoring—choosing what to ignore and where to invest one’s limited attentional capacities. We review three types of cognitive strategies for implementing critical ignoring:
- self-nudging, in which one ignores temptations by removing them from one’s digital environments;
- lateral reading, in which one vets information by leaving the source and verifying its credibility elsewhere online;
- and the do-not-feed-the-trolls heuristic, which advises one to not reward malicious actors with attention.
We argue that these strategies implementing critical ignoring should be part of school curricula on digital information literacy.
Good to give names to these practices, since we're all having to do them nowadays anyway...
(Via Stan Carey)
Tags: psychology trolls media kids internet literacy attention critical-ignoring ignoring papers via:stancarey