I'm uncomfortable voting for David Norris for President. Here's why.
In November last year, he was a key voice in a Senate debate on the topic of "Protection of Intellectual Property Rights", where he quoted heavily from the flawed judgement by Mr. Justice Peter Charleton in the Warner, Universal, Sony BMG and EMI vs UPC case. (There are allegations that he called the debate after speaking to Paul McGuinness (U2's manager) and Niall Stokes (of Hot Press).)
In the debate, Norris quotes Mr Justice Charleton, saying:
'In failing to provide legislative provision for blocking, diverting and interrupting internet copyright theft, Ireland is not yet fully in compliance with its obligations under European law.' Norris then says: 'Irish law could be brought into alignment with the intention of the European directive through a simple statutory instrument.' [1]
Now, let me clarify my position -- I'm in favour of some means of resolving the level of piracy of music and movies which is widespread nowadays, and I believe there's a mutually agreeable way to do this. But what Norris and Mr Justice Charleton propose is not it. Here are the problems as I see them.
It Lets The Internet Filtering Genie Out Of The Bottle
The big one.
The problem is that any infrastructure for 'blocking, diverting and interrupting internet copyright theft' is effectively infrastructure for 'blocking, diverting and interrupting' any communication on the net. We have to be very careful about how this is permitted, as it'll very quickly suffer "feature creep" and become a general-purpose censorship system -- the Great Firewall Of Ireland. As Damien Mulley put it:
'first they’ll start with the Pirate Bay. Then comes Mininova, IsoHunt, then comes YouTube (they have dodgy stuff, right?), how long before we have Boards.ie because someone quoted a newspaper article or a section of a book? And don’t think they’ll stop there too, any site that links to The Pirate Bay and the others on the hate list will probably be added to the list too...'
In Australia, the anti-child-porn filtering system was quickly used to block gambling websites, gay and straight porn sites, political parties, Wikipedia entries, Christian sites, Wikileaks, and a dentist; in Thailand, a similar system was used to block criticism of the royal family.
Will It Help? I Don't Think So
Norris:
'As long as Irish law is deficient, Mr. Justice Charleton has found that all creative Irish industries are losing money.'
This is quite a hilariously overblown and sweeping statement. ALL creative Irish industries? What qualifies as a 'creative' industry? I suspect some in this country have been involved in industrial acts of creation that made money. ;)
While they're not Irish, the well-known indie label Beggar's Banquet has gone on the record as stating the opposite where the current music situation is concerned --
"There's fewer gatekeepers now. We don't have to knock on a TV station's door or a radio station's door and it's made us far more competitive. [...] There's a wide highway in front of us we can go speeding down, and it wasn't there even two years ago. It means the majors are looking at a world where only 35 Gold Albums a year are certified compared to ten times that recently. But going above Gold in the US is not a problem for us."
So it appears a 'creative' industry (albeit in the UK) is finding things not quite so bad.
Norris again:
'the facts were established in the judgment of Mr. Justice Charleton in which he stated: “Between 2005 and 2009 the recording companies experienced a reduction of 40% in the Irish market for the legal sale of recorded music.” That is a devastating blow. [...] He went on to state: “Some 675,000 people are likely to be engaged in some form of illegal downloading from time to time.”'
Without quite lining up one statement with the other, this reinforces the impression that the only reason the recording companies have seen these drops in revenues is due to internet-borne piracy. However, quoting the brilliant Mumblin' Deaf Ro on the topic of lies, damn lies, and music biz statistics:
'The drop in the value of Irish retail music sales was 11.7% between 2008 and 2009, which is significantly less than the 18% overall drop in retail sales for the economy that year. Digital album sales have increased by 30% since 2007 both in terms of volume and market value.'
So in other words, between 2008 and 2009, Irish retail music sales outperformed the retail sales economy as a whole!
In addition, Ro provides the following BPI figures for UK market volumes over the 2005-2009 period:
Year Albums Singles
2005 159.0m 47.9m
2006 154.7m 66.9m
2007 138.1m 86.6m
2008 133.6m 115.1m
2009 128.9m 152.7m
It's clear that singles sales went through the roof, more than tripling. Album sales did drop however, but nowhere near by 40% -- and this coincided with the general drop in the prevailing global economy around that time. He also notes that digital sales in the UK went through the roof globally on a number of metrics in 2009.
While this does not provide figures for the Irish market, I'm at a loss as to how it could be radically different -- Irish and UK consumers have pretty similar musical tastes and consumption habits, I would guess.
Here's a theory: perhaps the issue could be that "Irish" music sales are associated with bricks-and-mortar music shops selling the physical product, whereas digital music sales are associated with online services based outside Ireland, and an Irish buyer buying an album at 7digital.co.uk, or on iTunes, isn't counted as an "Irish retail sale"? Could the problem be that we don't have any significant Irish shops selling music online, I wonder?
Bricks-and-mortar music shops, such as ex-Senator Donie Cassidy's "Celtic Note" (who coincidentally was quite vociferous in that Seanad debate), are indeed hurting in this new model of music consumption -- and that's a problem. But given that good, working digital music sales systems are in operation, it doesn't necessarily appear to be due to massive volumes of internet-borne piracy, going by these figures.
Essentially, internet piracy is a convenient bogeyman, especially for the technophobic old guard, but may have little bearing on the current woes of the Irish record industry and bricks-and-mortar music shops.
(Update: a couple of days after this was posted, a pair of economists at the LSE have said basically the same thing.)
Audible Magic Won't Work For Long Anyway
Audible Magic, which Norris suggests is IRMA's favoured filtering system, received the following verdict from the EFF back in 2004:
'Should Audible Magic's technology be widely adopted, it is likely that P2P file-sharing applications would be revised to implement encryption. Accordingly, network administrators will want to ask Audible Magic tough questions before investing in the company's technology, lest the investment be rendered worthless by the next P2P "upgrade."'
Naturally, encryption is widespread nowadays, so this may already be the case.
Internet Censorship Harms Our Global Image
As Adrian Weckler points out:
'do we really want to send out the message that, digitally, we're the new France? Come to think of it, do we want to tell Google, Facebook, Apple and Twitter that, digitally, we're the new Britain?'
Right now, more than ever, we need to put out an image that we're ready to do business on our end of the internet. Mandatory censorship systems don't exactly support this.
In Summary
So in summary, I would hope to see a more balanced approach to the issue from Norris. Most of the problematic statements in his speech were directly sourced from Mr. Justice Charleton's flawed judgement, but some critical thinking would be vital, I would have thought. The fact that this was lacking, particularly given the allegations of heavy music-biz lobbying beforehand, leaves me feeling less inclined to vote for him than I would have been before, particularly since I haven't heard any clarification on these issues.
([1]: Funnily enough, an SI similar to this was nearly sneaked through a couple of weeks ago, according to reports.)
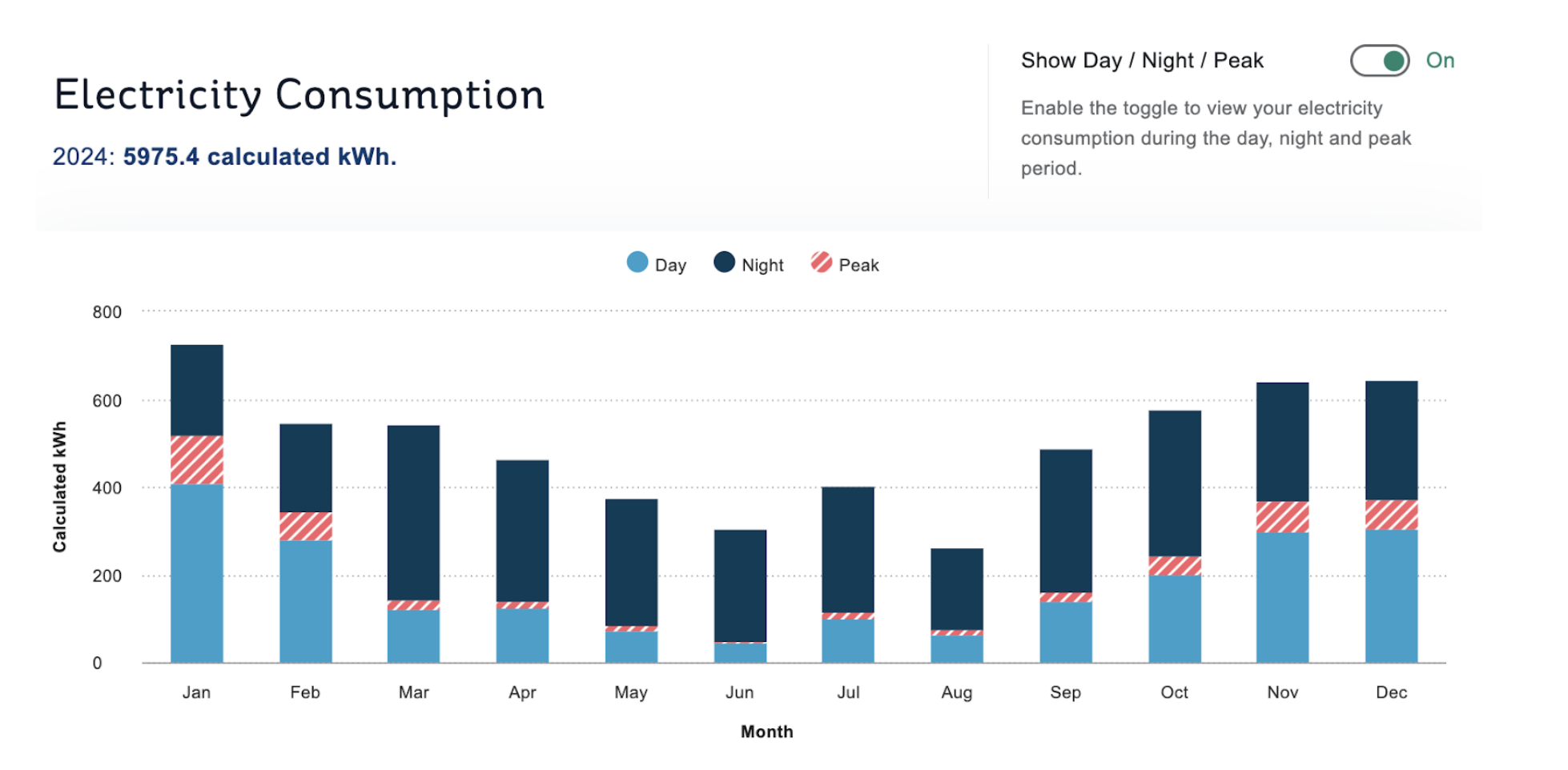
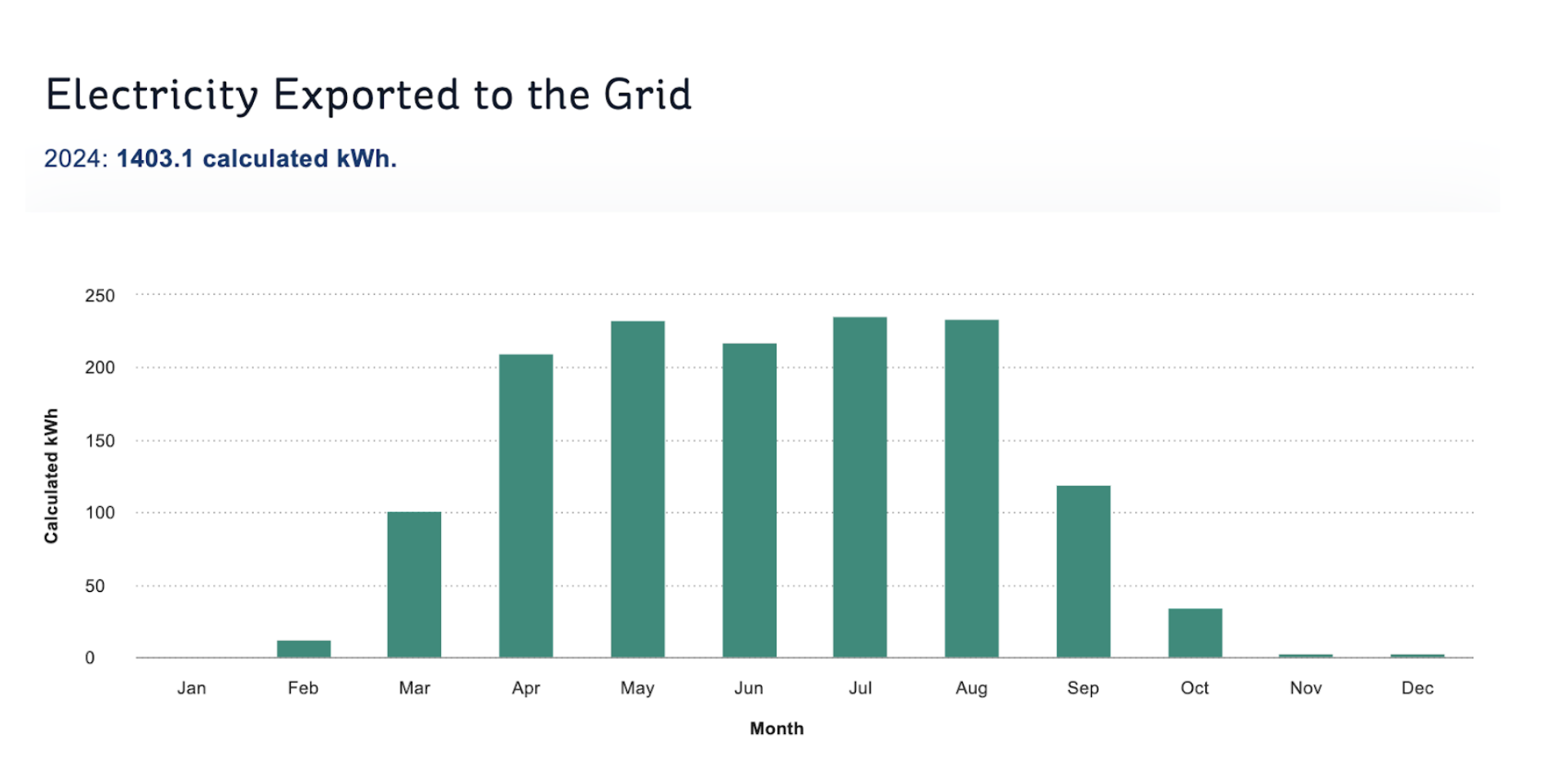
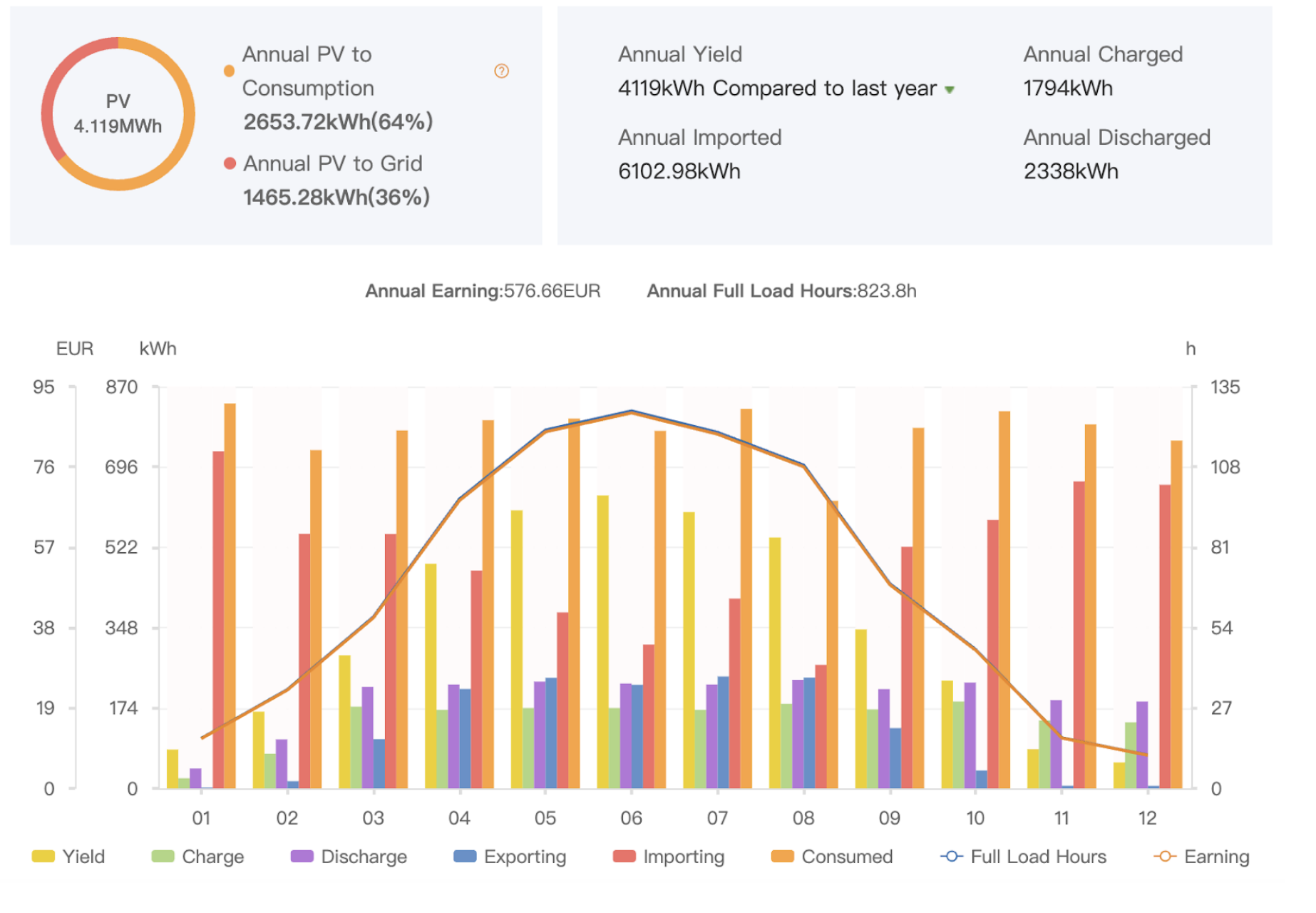
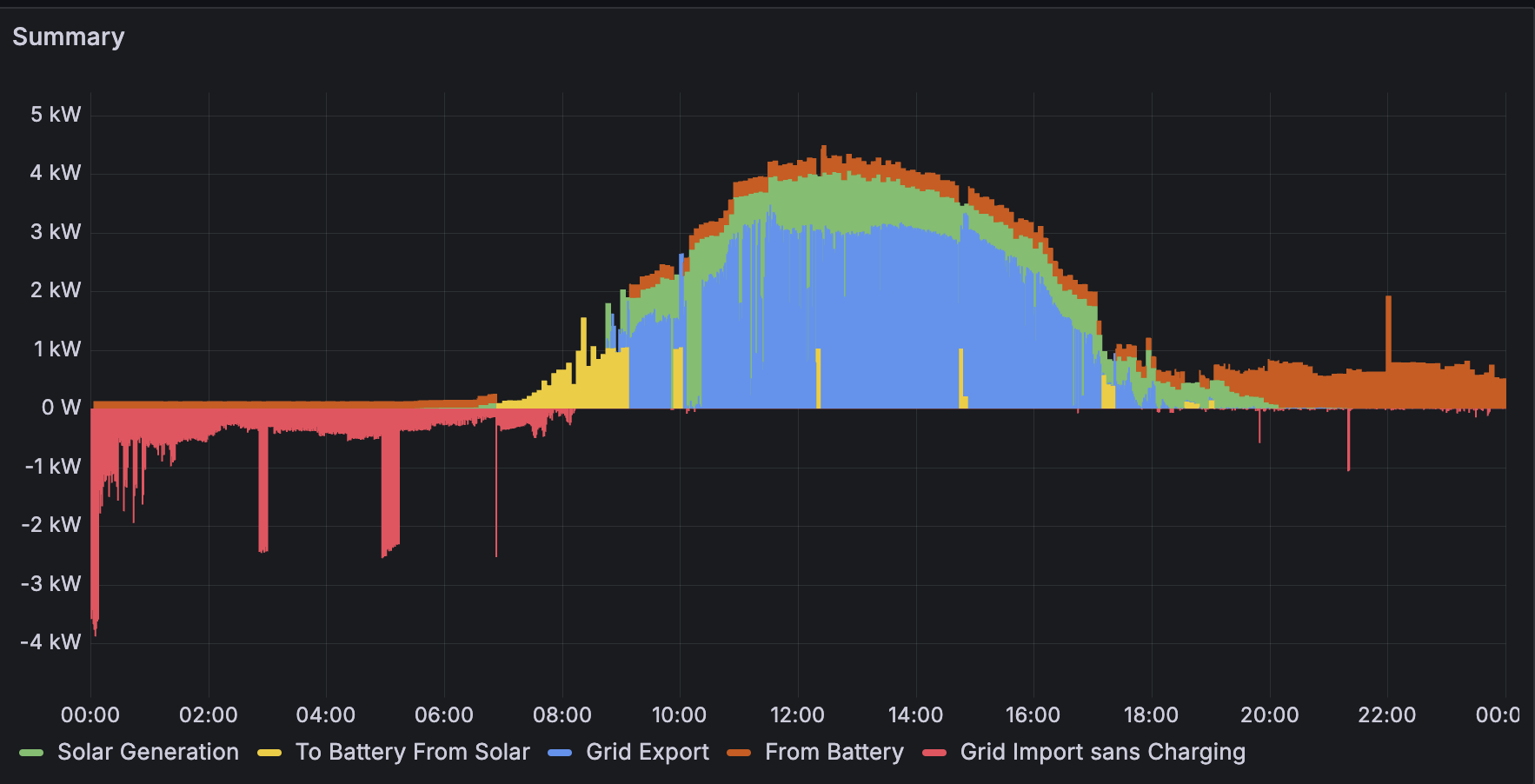






 It's pretty common for apps to require "configuration" -- external files which can contain settings to customise their behaviour. Ideally, apps shouldn't require configuration, and this is always a good aim. But in some situations, it's unavoidable.
It's pretty common for apps to require "configuration" -- external files which can contain settings to customise their behaviour. Ideally, apps shouldn't require configuration, and this is always a good aim. But in some situations, it's unavoidable.

 I'm not a fan of Guinness. It's a good beer, but monotonous when it's the only thing available. This, from
I'm not a fan of Guinness. It's a good beer, but monotonous when it's the only thing available. This, from 









 A while back, I linkblogged about
A while back, I linkblogged about 
 Somehow or other, I seem to have won the
Somehow or other, I seem to have won the  Eircom has been forced to implement "3 strikes and you're out",
Eircom has been forced to implement "3 strikes and you're out", 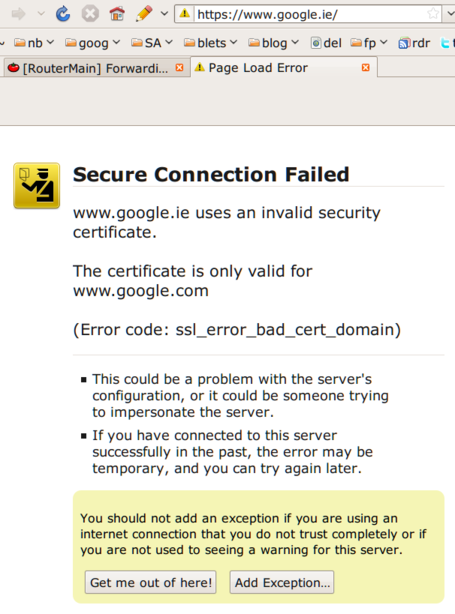



{kind=link}